

David Loker
November 26, 2025
8 min read
November 26, 2025
8 min read
Share
Cut code review time & bugs by 50%
Most installed AI app on GitHub and GitLab
Free 14-day trial
TL;DR: It doesn’t just write patches; it writes a complete argument for every change. When
is right, it’s spectacularly right. When it’s wrong, it still sounds right.
All of CodeRabbit’s models follow the same structural blueprint: a short headline, an explanation, and a patch. However, Gemini 3 uses that frame differently. It fills every inch of space with evidence, preconditions, and causal reasoning. Each review reads like a technical brief wrapped around a diff.
Gemini 3 is confident, detailed, and relentlessly specific. Its comments read like they were written by a senior engineer who wants to fix the issue and demonstrate why the fix is necessary. That density is its defining trait. Every comment feels significant, even the ones you might not ultimately act on.

We evaluated Gemini 3 using CodeRabbit’s standard benchmark: 25 pull requests seeded with known error patterns (EPs) across C++, Java, Python, and TypeScript. Each comment was scored by multiple LLM judges and hand-validated by our engineers. We measured precision, important-share, and signal-to-noise ratio (SNR), the same metrics used in all of our model evaluations.
We also assessed tone, length, and style, since how a model communicates can affect whether developers accept its suggestions.
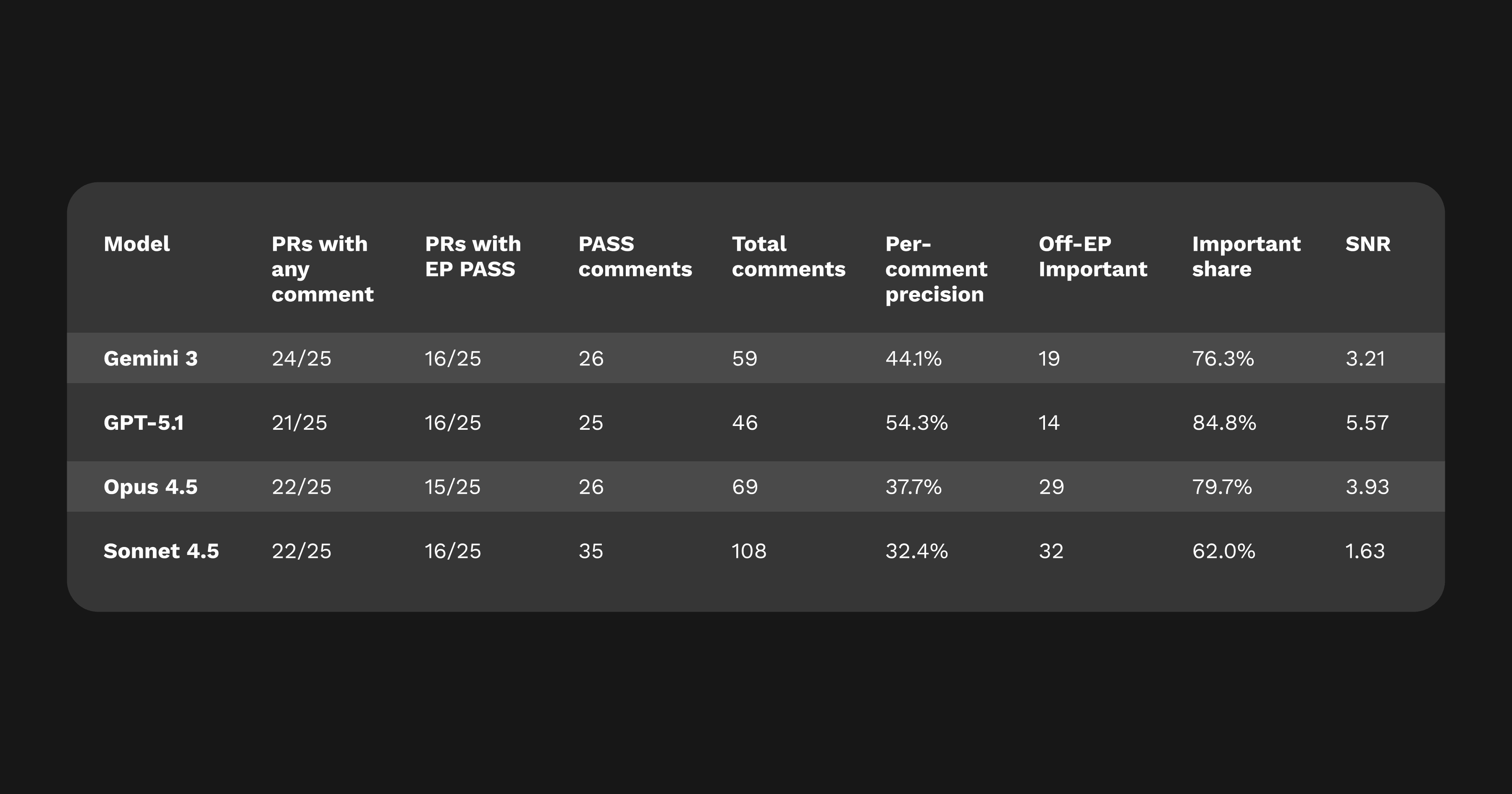
Interpretation: Gemini 3 sits in the middle of the group for precision but provides excellent real-bug coverage. Roughly three of every four comments are important (critical or major). Its SNR of 3.2 puts it close to Opus 4.5 in reliability, but Gemini 3 expresses itself with greater conviction and detail.
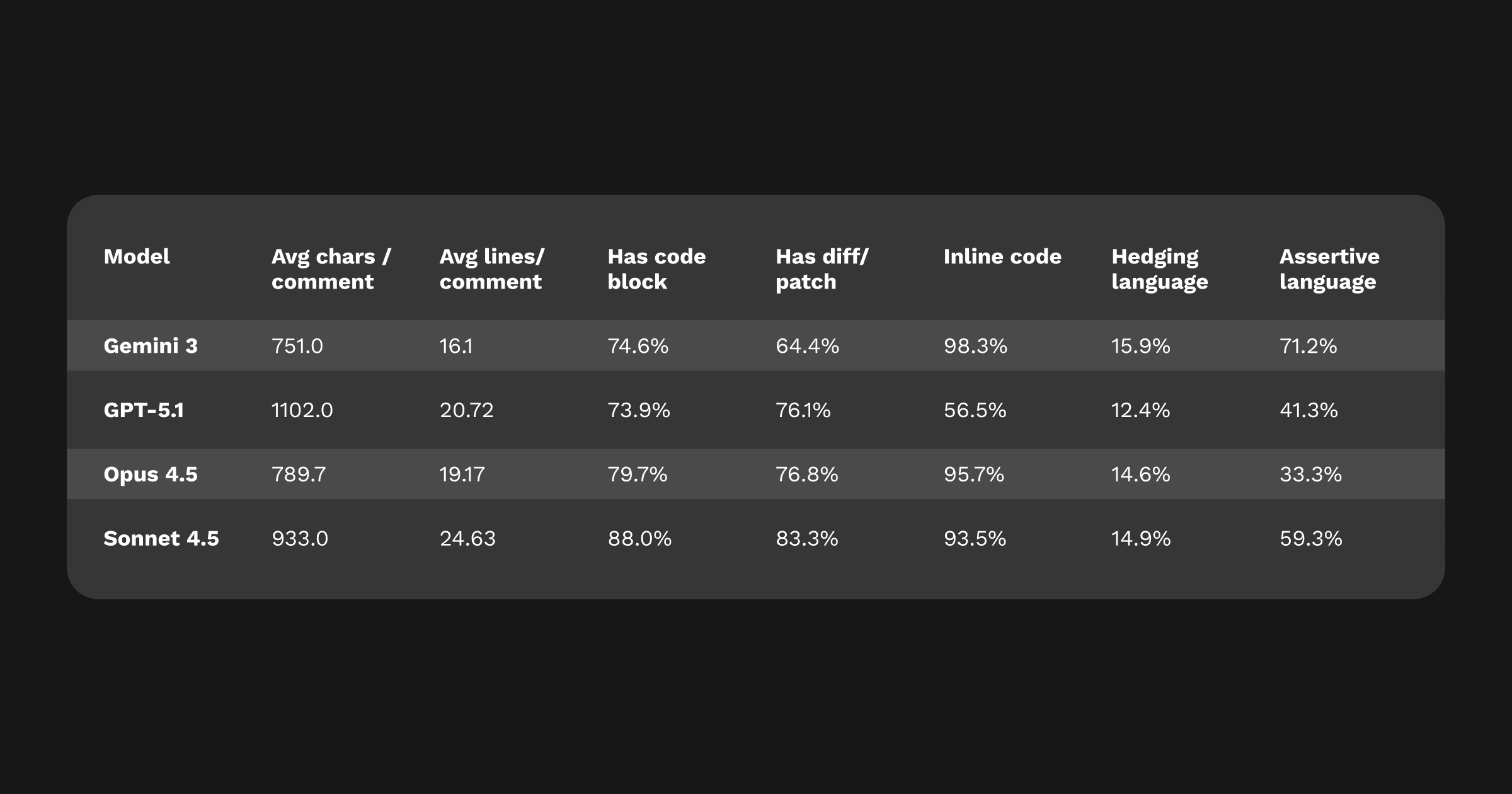
Tone summary: Gemini 3 is the most assertive of the four. It communicates with confidence, and for the most part, that confidence is justified. Even when it makes a mistake, the comment sounds credible enough to make developers stop and re-check the code, which may add to its practical value but may be confusing for some.

Gemini 3 compresses an exceptional amount of reasoning into compact comments. The average comment is only 16 lines long, yet each one unpacks a complete causal chain: what broke, why it happened, and how to fix it.
For example, in a concurrency issue found in a C++ worker pool, Gemini 3 doesn’t simply say “missing lock.” It reconstructs the sequence: unlock, wait, missed signal, dead thread. Then it provides a single-line patch that resolves the race. In another TypeScript review, the model identifies that MAX_SAFE_INTEGER disables cache eviction, explains the performance risk, and proposes an LRU fallback. These are not stylistic suggestions. These are corrections that improve program reliability.
This combination of density and accuracy defines Gemini 3’s personality. Every comment is an argument, and most of those arguments hold up under scrutiny.

Reading Gemini 3 feels distinct from reading any other reviewer. It is confident and structured, but its reasoning is particularly dense. Each comment reads like a detailed technical review from a lead engineer who insists on context before approving a change. Comments often open with a directive such as “Fix this race condition,” then expand into a clear explanation, referencing specific files and ending with a patch. The result feels like an expert walking you through both the problem and the fix.
Developers describe Gemini 3 as a reviewer that sounds sure of itself and provides evidence to support its claims. Its direct tone can feel intense, especially compared to GPT-5.1’s measured precision or Opus 4.5’s calm logic. However, each comment feels like a mini design review, explaining what to change, why it matters, and what trade-offs exist.
The model’s high information density requires careful reading, but it provides proportionate insight. Even when wrong, Gemini 3 often reveals something valuable about hidden edge cases or architectural assumptions.
1. Density correlates with correctness. Longer comments (top half by length) pass more often, with 53% precision compared to 34% for shorter comments. Important comments (critical or major) average 847 characters, nearly twice the size of unimportant ones (442). When Gemini 3 takes time to elaborate, it is typically accurate.
2. Tone tracks severity. Assertiveness rises with severity: 92% of major and 67% of critical comments are assertive, while only 36% of minor comments are. Hedging increases to 36% on minor issues. The model uses its strongest voice for the most serious problems, which makes it effective for triage.
3. Confidence correlates with quality. Assertive comments pass more frequently (47.6%) than neutral (36%) or hedged (33%) ones. Gemini 3’s confidence is generally supported by evidence rather than overstated.
4. Patches indicate reliability. When a diff or code block appears, the precision rate improves. Over 70% of assertive comments contain diffs, compared with only 17% of hedged comments. The presence of a patch often signals that the model’s reasoning is grounded in the actual code.

Gemini 3’s strongest areas are concurrency and system correctness. It frequently detects interleaving and synchronization issues that other models overlook. It excels at diagnosing the why behind a bug:
Thread-safety: Describes lost wakeups and inconsistent locking with narrative precision, then offers a concise patch.
Lifecycle management: Identifies missing shutdown hooks or unclosed resources and recommends explicit cleanup.
Algorithmic stability: Corrects comparator logic and off-by-one ranges to restore invariants.
System configuration: Finds default values that disable expected behavior and recommends practical limits.
Each of these shows how Gemini 3’s detailed reasoning leads to direct, verifiable fixes.
Gemini 3’s conviction can occasionally go too far. On stylistic or low-severity issues, it may overstate importance. Some comments labeled “Critical” are actually minor or aesthetic. Its assertive tone can make small findings sound urgent. This model performs best when paired with experienced reviewers who can distinguish critical bugs from overconfident advice.
Even its overreaches tend to highlight genuine inefficiencies or readability concerns. Few comments are without value.
Gemini 3 trades brevity for understanding. It does not simply provide a fix; it delivers a short investigation. This depth makes it particularly valuable for large, complex systems. Precision measures whether a model hits the target, but density measures how much a developer learns by reading it.
In production environments, that difference matters. A concise reviewer like GPT-5.1 delivers quick, targeted notes. Gemini 3, by contrast, provides comprehensive reasoning that increases confidence and reduces the likelihood of missing subtle defects.
Let's put it this way, “You don’t skim Gemini 3. You study it.”
| Use it when... | Because... |
| Concurrency-heavy or resource-sensitive code | It excels at identifying synchronization and lifecycle issues. |
| Depth over brevity | Longer, more detailed comments correlate with accuracy. |
| You need actionable patches | Around 65% of comments include ready-to-apply diffs. |
| You can manage assertive tone | Its confidence is helpful but occasionally overstated. |
| You are mentoring newer developers | Each comment serves as both a fix and an educational note. |
Gemini 3 is not ideal for superficial or stylistic reviews. It is best used when precision, explanation, and insight are more important than speed.
Gemini 3 does more than fix code; it presents a logical case for every fix. Each comment is a complete story of cause, effect, and resolution. When it is correct, it feels like reading a senior engineer’s deep-dive analysis. Even when it is wrong, it provides insight into how to think about the problem.
Takeaway: If GPT-5.1 is the decisive teammate and Opus 4.5 the disciplined architect, Gemini 3 is the dense engineer who delivers a fully reasoned diff that is confident, comprehensive, and intent on proving its point.
Want to try out CodeRabbit? Get at 14-day free trial!



