CodeRabbitがClaude Marketplaceに登場!Claude Marketplaceの発表を読む

Atsushi Nakatsugawa
April 16, 2026
2 min read
What Claude Opus 4.7 means for AI code reviewの意訳です
金曜日にレビュアーが40ファイルのPRを急いで確認したせいで出荷されてしまうバグ。3つのファイルの奥深くに埋もれた競合状態で、午前2時に誰かが呼び出されるまで誰も追跡しないもの。それがAIコードレビューが埋めるために作られたギャップです。Claude Opus 4.7により、そのギャップはかなり狭くなりました。
CodeRabbitのレビューエンジンは単一のモデルに依存していません。複数のラボのフロンティアモデルをアンサンブルで実行し、レビューパイプラインの異なる側面に異なるモデルを選択しています。各モデルは実際のコードでの評価を通じて、そのポジションを獲得します。新しいフロンティアモデルがリリースされると、現在のアンサンブル内のすべてのモデルに対してベンチマークを行い、どこで優れ、どこで劣るかを確認します。
私たちは、CodeRabbitのプロダクトコードレビューパイプラインに対してテストを行ってきました。その結果は、わずかな改善どころではありませんでした。Opus 4.7を、実世界の多数のオープンソースプルリクエストにまたがる100の評価ポイントで正面から比較した結果として、Claude Opus 4.7は、より多くの実際のバグを発見し、より実用的なフィードバックを生成し、これまでテストしたどのモデルよりもファイルをまたいだ推論に優れています。
結果に入る前に、コードレビューモデルをどのようにベンチマークしているかを理解することが重要です。方法論は結果と同じくらい重要です。
私たちの評価フレームワークは、エラーパターン(Error Patterns。以下EP)と呼ばれるものを中心に構築されています。これは、主要なオープンソースプロジェクトの実際のプルリクエストから抽出した、100の既知の問題のキュレーションされたセットです。各EPは、実際のPR内の特定の検証済み問題にマッピングされます。Goサービスの競合状態、Reactコンポーネントのnullチェック漏れ、Railsコントローラーの認可バイパスなどです。
テストするすべてのモデルについて、4つのコア次元を測定します。
Opus 4.7を、まったく同じ評価基準で、同じ100のEPに対して、同じPRで現在の本番ベースラインと比較してスコアリングしました。特定のモデルを優遇するようなチェリーピッキングや特別なプロンプティングは行っていません。
CodeRabbitにOpus 4.7を統合すると、追跡しているさまざまな指標でレビュー品質が向上します。
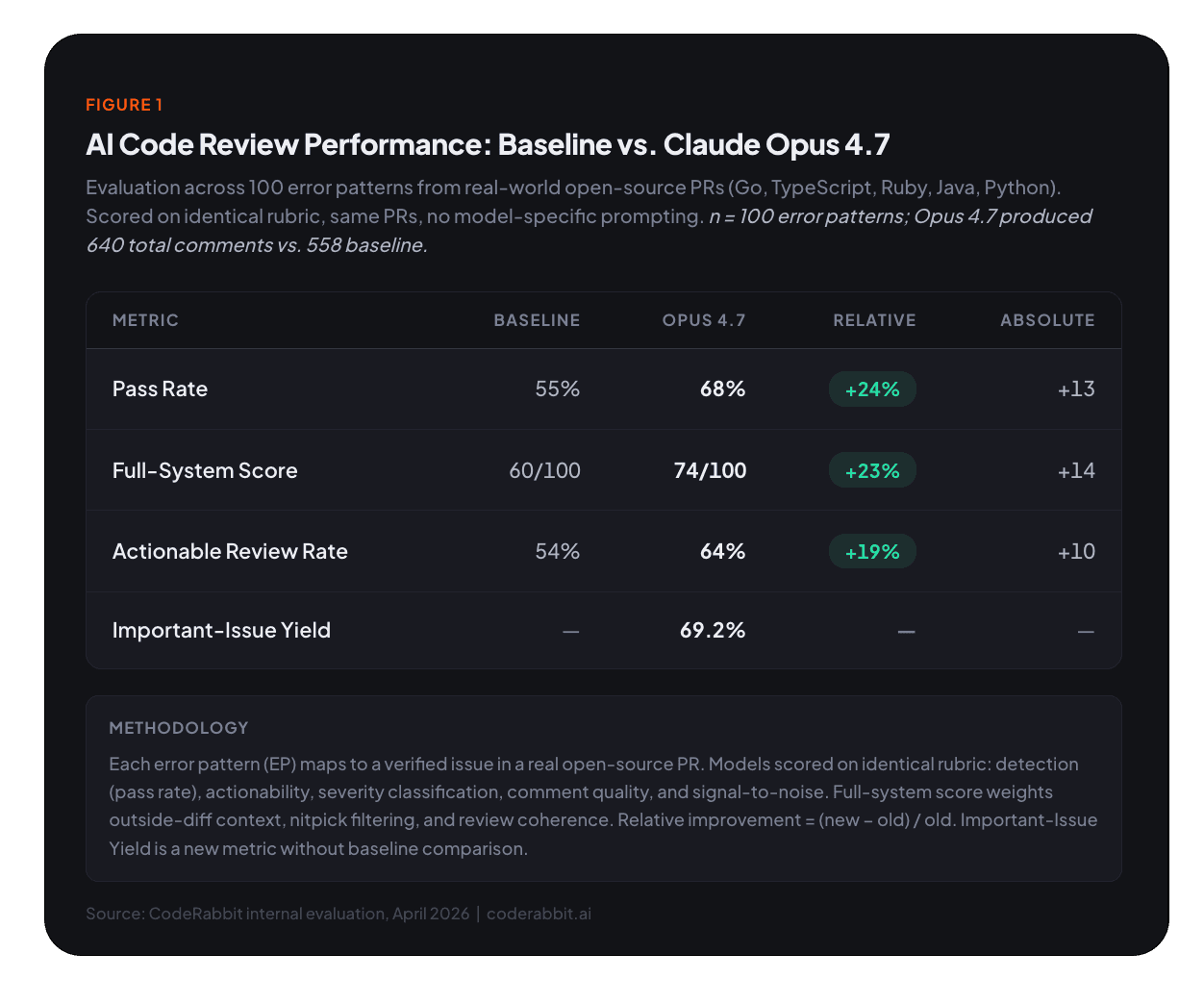
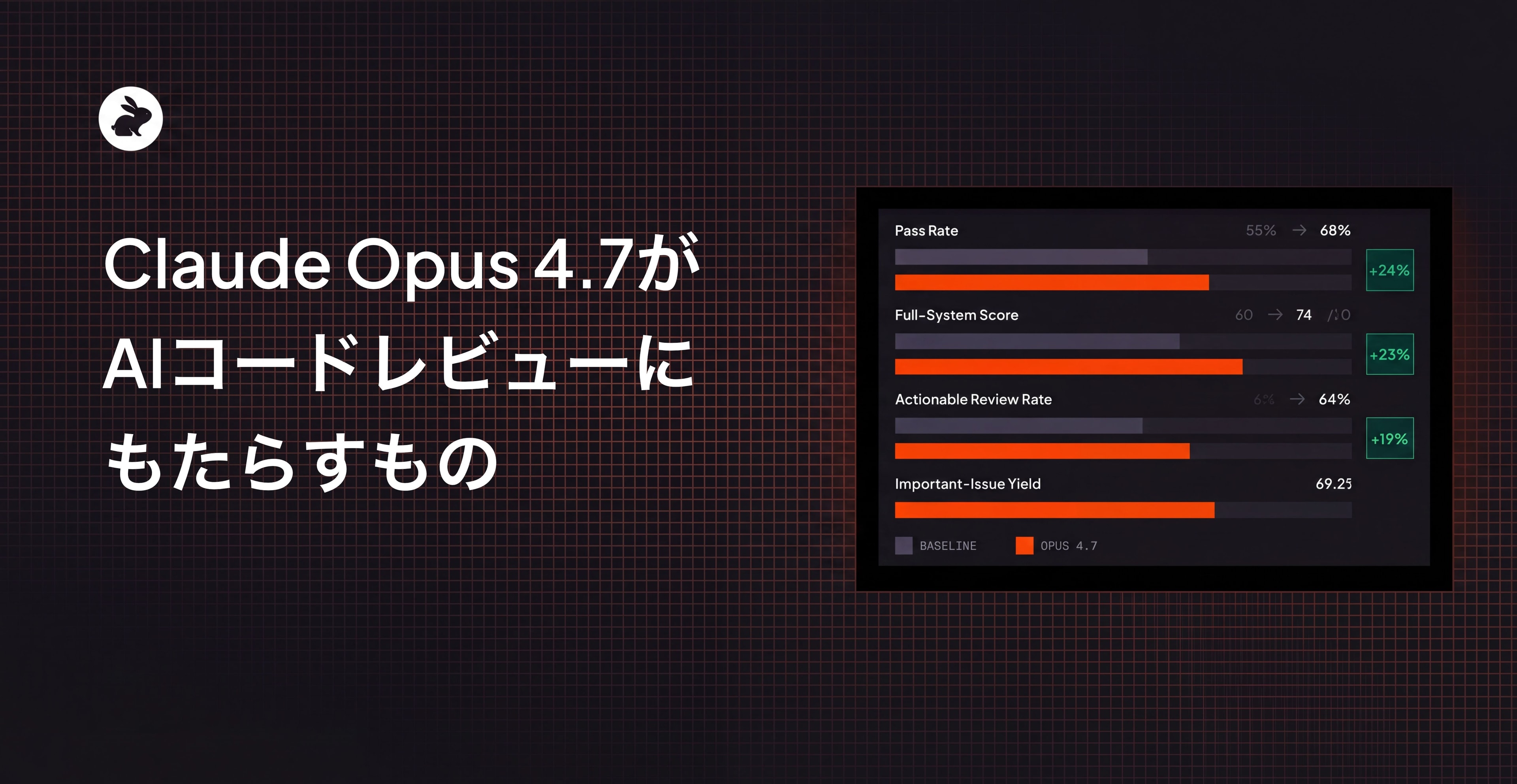
コアの評価において、モデルが特定のPR内の既知の問題を検出できるかどうかについて、CodeRabbitの現在のコードレビューハーネスにOpus 4.7を統合すると、100の評価ポイント中68でパスしました。ベースラインの55からの増加です。これは、重要なバグを見つけるモデルの能力における24%の相対的改善です。
実用的に表現すると、週に20のPRをマージし、それぞれに少なくとも1つのレビュー可能な問題が含まれているチームを想像してください。ベースラインモデルでは、それらの問題のうち約11件が検出されます。Opus 4.7では、その数は約14件に跳ね上がります。四半期で見ると、本番環境に到達する前に約36件の追加バグが検出されることになります。
フルスコアリングシステム(diff外のコンテキスト、nitpickフィルタリング、全体的なレビューの一貫性を考慮)を重ねると、差はさらに広がります。Opus 4.7の統合スコアはベースラインの60/100に対して74/100、23%の相対的改善です。
この指標は、生のバグ検出よりも微妙なものを捉えています。モデルはバグを検出しても、混乱を招く方法で行ったり、間違った行を参照したり、無関係なノイズの中に発見を埋もれさせたりする場合があります。フルシステムスコアはそれらの失敗モードにペナルティを課し、一貫性があり、適切にターゲットされ、より広いPRの中で適切にコンテキスト化されたレビューを評価します。Opus 4.7のフルシステムスコアが生のパス率以上に改善したという事実は、検出と並んでプレゼンテーションの品質も改善したことを示しています。レビューはより一貫性があり、ターゲットがより適切で、コンテキスト化が改善されています。
640件のコメントのすべてが評価者によって実用的と判定されました。つまり、各コメントには開発者が対応するのに十分な情報が含まれていました。しかし、EP固有の実用性(実用的なコメントが付随的な懸念ではなく実際にターゲットの問題に対処しているかどうか)で測定すると、54%から64%に跳ね上がりました。
これは「このファイルのどこかに問題があります」と言うレビュアーと、「47行目はユーザーがnilのときにpanicします。42行目のガード句がadminロールパスをカバーしていないためです。修正するdiffはこちらです」と言うレビュアーの違いです。どちらも技術的には実用的です。しかし、あなたの時間を節約するのは後者だけです。
これは評価の中で最も印象的なデータポイントの一つです。Opus 4.7が生成した全コメントの約70%が重要と分類されました。スタイルのnitpickや見た目の提案ではなく、実質的なバグ、セキュリティリスク、または正確性の問題にフラグを立てたことを意味します。
それらの443件の重要なコメントのうち、367件はターゲットの評価ポイント以外でモデルが発見した所見でした。すべての重要な出力の82.8%が、同じコードをレビューしている間にモデルが自発的に発見した問題から来ています。言い換えれば、Opus 4.7はターゲットを絞ったテストというよりも、指示されたコードを見ながら周辺の問題に気づく徹底的なレビュアーのように振る舞います。
参考として、ベースラインモデルは合計558件のコメントを生成しました。Opus 4.7の統合では640件を生成し、約15%のボリューム増加です。しかし、重要な問題の密度こそが差別化要因です。ノイズであればコメントが増えても意味がありません。重要なコメントが増えることは、まったく別の話です。
上記のスコアはOpus 4.7が優れていることを確立しています。以下ではなぜそうなのか、そしてこのモデルがあなたのコードをレビューするとき実際にどのように見えるかを説明します。私たちは個々のコメントを読む作業にかなりの時間を費やし、言語やコードベースを問わず一貫していくつかのパターンが浮かび上がりました。

評価セット全体を通じて、モデルは具体的な競合状態、nil/panicパス、認可の失敗、ブラックリストバイパス、XSSおよびSSRFチェーン、レスポンス形状の不一致、ライフサイクル/データ損失バグを一貫して特定しました。
Goのコードベースでは、モデルはgoroutine間の並行アクセスパターンを追跡して実際の競合状態を特定しました。単に「これは競合状態があるかもしれない」ではなく、「goroutine Aが137行目でcache.entriesに書き込む一方、goroutine Bが140行目で同期なしに読み取っており、並行負荷下でpanicします」というレベルです。特定のデータ構造、特定の行、特定の障害モードを名指ししました。
TypeScript/Reactコードでは、イベントハンドラのライフサイクルを追跡して状態管理のバグを発見しました。useEffectのクリーンアップ関数が非同期フェッチとどのように相互作用するかを追跡し、古いクロージャがアンマウントされたコンポーネントに状態更新を引き起こす正確なウィンドウを特定し、修正としてキャンセルトークンパターンを提案しました。
Ruby on Railsコントローラーでは、パラメータ処理のエッジケースから生じる認証バイパスベクターを特定しました。人間のレビュアーが金曜日の午後に見落としがちですが、攻撃者は土曜日に見逃さない類の微妙な許容性です。
Java(特にKeycloak)では、サービスインターフェースとその実装間のコントラクトの不一致を検出し、複数の抽象化レイヤーを通じてランタイム例外が表面化する箇所を追跡しました。
Python(Sentry)では、例外が広すぎるスコープでキャッチされているサイレント障害パスを特定しました。データ処理パイプラインがエラーを飲み込み、可視的なアラートなしに不完全な結果を生成する問題です。
最も印象的な能力の一つであり、拡張されたコンテキストウィンドウから最も恩恵を受けるのは、ファイル間で所見を関連付けるモデルの能力です。diffが与えられると、ヘルパーレベルのコントラクトから下流の破壊を追跡し、関連するメソッド、ハンドラー、プロバイダー間の動作を比較します。
Opus 4.7は、そのパラメータがPR作成者が更新し忘れた2つの下流の呼び出し元によって使用されていたこと、そしてそれらの呼び出し元の1つがエンタープライズアカウントの請求計算を壊すデフォルト値にサイレントにフォールバックすることを教えてくれます。
私たちの分析でこのパターンが確認されました。モデルは「ヘルパーレベルのコントラクトを下流の破壊に関連付け、関連するメソッド、ハンドラー、プロバイダー間の動作を比較する」ことが多いのです。これは5つの異なる言語エコシステムにまたがる数十のレビューセッションで一貫して観察されました。
レビュースタイルは非常にコード中心であり、ここが実用的な開発者体験が光る部分です。
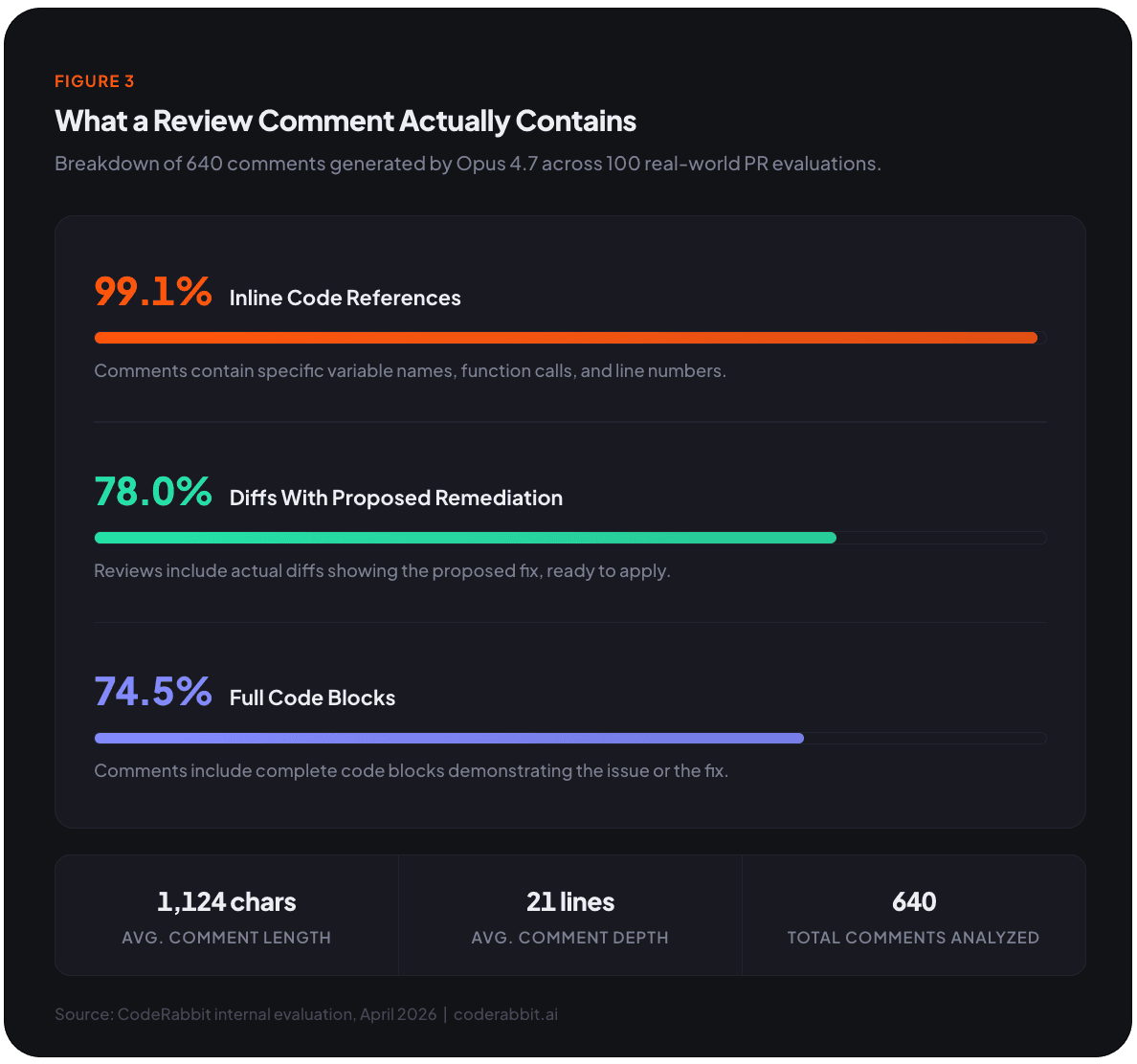
実際には、ほとんどのコメントがすぐに適用可能な修正とともに届きます。平均的なコメントは21行にわたる1,124文字で、ドライブバイの注釈というよりもミニデザインレビューのように読めます。典型的なコメントは強調の判定スタイルのサマリー(「キャッシュ無効化における競合状態」)で始まり、簡潔なメカニズム/影響の説明(特定のコードパスを追跡する2〜3段落)が続き、折りたたみ可能な<details>ブロックに包まれた具体的なdiffで締めくくられます。
以前のClaudeモデルをコードレビューに使ったことがある方は、Opus 4.7のトーンが明らかに異なると感じるでしょう。Anthropicはそれを「より直接的で意見を持った、検証先行のフレーズが少ない」と表現しています。私たちの評価はこの変化を定量化しています。
Opus 4.7のレビューコメントは77.6%の断定率とわずか16.5%のヘッジ率を持っています。問題の太字で判定スタイルのサマリーで始まり、簡潔なメカニズム/影響の説明が続き、具体的なパッチを提示します。言語は明確な命令形を使用します。「nil入力に対してガードする」「並行アクセスを防止する」「処理前に入力を検証する」といった表現で、暫定的な提案ではありません。
私たちのトーン分析はそれをうまくまとめています。「コメントは詳細なミニコードレビューのように読めます。問題の太字で判定スタイルのサマリーで始まり、1〜3の説明段落が続き、diff形式の具体的なパッチを提示します。トーンは自信に満ち、指示的であり、暫定的なフレーズではなく明確な命令形を使用しています。」
メンテナーにとって、これは歓迎すべき変化です。モデルが「nilを確認することを検討してもよいかもしれません」ではなく「nil入力でpanicします」と伝えてくれると、認知的なオーバーヘッドが減り、フィードバックへの対応がより速くなります。忙しいレビューキューでは、その直接性が1日に何十ものコメントにわたって積み重なります。
残っているヘッジは適切に配置されています。これは特に、主観的またはドメイン固有の決定の周りに現れます。例えば、ローカライゼーション文字列が潜在的に不正確であるとフラグを立て、「ネイティブスピーカーに確認してもらってください」と提案するような場合です。これは適切な謙虚さです。モデルは証拠がある場合は自信を持ち、ない場合は慎重です。
実際に動作を見てみませんか? 次のPRでCodeRabbitを試してください - 無料で始められ、クレジットカードは不要です。あなた自身のコードでOpus 4.7搭載のレビューをご確認ください。
ベンチマークは、評価基準上でモデルがどのように機能するかを教えてくれます。しかし、実際にモデルと一緒に何かを作る感覚は教えてくれません。私たちのエンジニアリングチームはコードレビュー以外のコーディングタスクでもOpus 4.7をハンズオンで使用しており、いくつかのパターンが浮かび上がりました。
最初に気づくのは、モデルがコミュニケーションを取りたがるということです。作業中、モデルは何をしているか、なぜか、どの変数を変更しているか、どのファイルに触れているか、各ステップでの推論は何かを逐一報告します。トーンは会話的ではなく、戦術的です。すべてのトークンが情報を運び、温かみよりもコンテキスト転送のために最適化されています。
AIコーディングアシスタントでの作業が初めてなら、これは素晴らしいことです。学習ツールとしても機能するランニングコメンタリーが得られます。しかし、簡潔でさっさと済ませるやり取りに慣れている経験豊富な開発者にとっては、やや過剰なコミュニケーションに感じることがあります。説明を流し読みしてコード出力に集中することを学ぶ調整期間があります。レビューベンチマークで測定したのと同じ深さが引き継がれています。
Opus 4.7はタスクの複雑さに対する強い感覚を持っています。単純なもの(変数のリネーム、ガード句の追加、ユーティリティ関数の記述)を与えると速く動きます。本当に難しいもの(ステートマシンのリファクタリング、認証フローの再設計、循環依存の解消)を与えると推論にさらに時間をかけ、その違いを感じることができます。複雑なタスクでも全体的な速度は以前のモデルより明らかに速いです。モデルはタスクがどれだけの思考に値するかを理解し、それに応じて割り当てているようです。そのため、些細な作業に対して過度に推論して時間を無駄にすることはありません。
実際には、これまで見たことのないスピードでタスクバックログを処理できることを意味します。単純な変更はあっという間に終わります。複雑な変更はより時間がかかりますが、より少ないバグとより良い構造で仕上がります。
最初の一連のハンズオンセッション全体を通じて、コード品質は一貫して高いものでした。初期の探索中に遭遇したバグは非常に少なく、通常AIが生成したコードの初回パスを悩ませる「動くが機能しない」タイプの失敗は顕著に少ないものでした。モデルは初回でロジックを正しく書くことが多いようです。
フロントエンド作業にはニュアンスがあります。Opus 4.7はUXのロジックには優れています。要素の配置、状態間のフロー、コンポーネントのインタラクティブな振る舞いなどです。しかし、デザインセンスは優れているとは言えません。生成されるUIは機能的で構造も良いですが、デザイン賞を受賞するようなものではありません。プロトタイプや社内ツールを構築しているなら問題ありません。コンシューマー向けプロダクトを構築しているなら、独自のデザインシステムを持ち込み、モデルをロジックレイヤーに使用することを想定してください。
驚いたことの一つは、Opus 4.7が不正確なプロンプトの解釈に非常に優れていることです。完璧に構造化された指示を書く必要はありません。曖昧であったり、不完全であったり、やや矛盾していたりしても、モデルは一般的に実際に意図したことを推測し、有用なものを生成します。実世界での使用では、開発者はタイピングよりも速く考えています。完璧なプロンプトの作成に時間をかけたくないのですが、Opus 4.7ならその必要はありません。
これはコードレビューのコンテキストでのベンチマークが示すものと一致しています。モデルは各指示を独立した命令として扱うのではなく、より広い意図とコンテキストについて推論しているように見えます。
私たちが観察したより興味深い振る舞いの一つは、Opus 4.7がタスク完了後に自分の作業を振り返ってレビューすることが多いということです。コードを生成し、問題をスキャンし、発見したものを修正しようとする、すべて依頼不要です。このセルフコレクションループは真に価値があります。初回パスで見逃したものを検出し、最終出力を改善します。
しかしデメリットもあります。モデルが考えすぎるケースがあるのです。問題のないクリーンなコードに「問題」を見つけ、触る必要のなかったセクションの作り直しを始め、不要な変更や新たな問題をプロセスの中で導入してしまうことがあります。モデルの徹底性は時として過剰修正に傾きます。開発者への実践的なアドバイスとしては、モデルのセルフ編集を他のコード変更と同じ精査で確認し、最初のパスがすでに正しかった場合は躊躇なく2回目のパスをロールバックすることです。
これは予想外でした。Opus 4.7はクリエイティブな作業が本当に得意です。タイトル、キャッチフレーズ、ネーミング案、クリエイティブコピーを依頼したところ、モデルはオリジナリティを感じる結果を生み出しました。
グラフィカルなタスクでも良い結果を出しました。画像、ロゴ、ベクターグラフィックス、ピクセルアートを、コードと推論で主に知られるモデルから期待される以上のクオリティと一貫性で生成しました。複数の役割を担う開発者(そしてほとんどの開発者がそうです)にとって、そのクリエイティブの幅は、コードとそれを説明するマーケティングページの両方に同じモデルを使えることを意味します。
完璧なモデルはなく、あなたが自分で発見するよりも、荒削りな部分について率直にお伝えしたいと思います。
criticalとmajorに偏る傾向があります。それらのラベルの多くは正しいですが、モデルは推測的なセキュリティ面、マイグレーションリスク、そのレベルの厳格な基準を満たさないテスト専用の失敗にもcriticalを適用します。同じコメントテキストが類似のコンテキスト間で異なる重要度ラベルを受けることがあり、私たちが平滑化する必要のあるアノテーションの不安定性を反映しています。開発者に届く前にこれらを正規化するため、ポスト処理パイプラインを調整中です。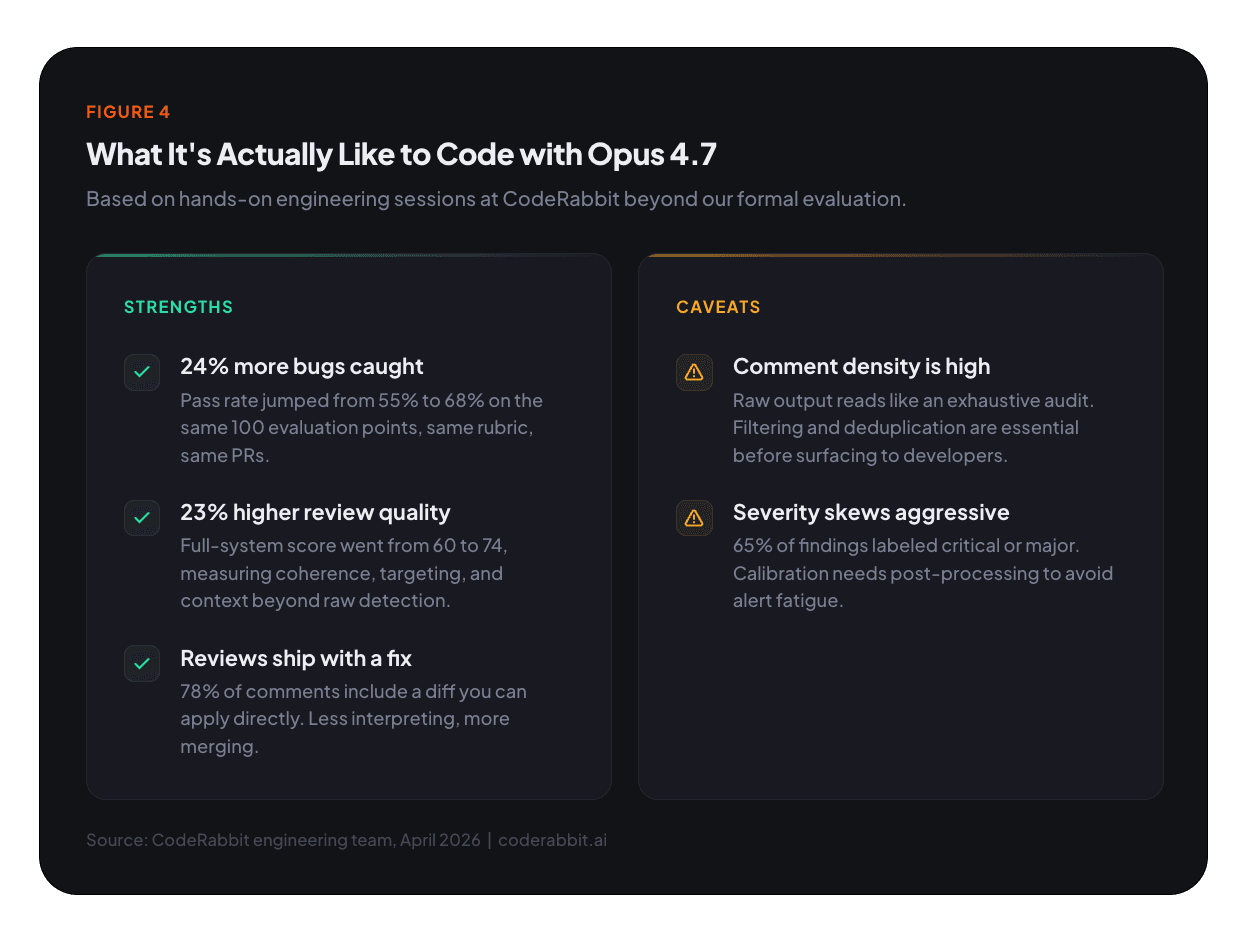
現在、Opus 4.7をレビューパイプラインに積極的に統合しています。ロールアウトに伴い、以下のことが期待できます。
Opus 4.7は、AIアシストコードレビューで可能なことのステップファンクションを代表しています。より強力な推論、より広いコンテキスト、より実用的な出力、設定可能な深さ。AIレビューと熟練した人間のレビューとのギャップは縮まり続けています。AIは人間のレビュアーを置き換えるのではありません。人間が時間を割けない領域をカバーしているのです。
まだCodeRabbitを試したことがないなら、これ以上ない良いタイミングです。2分以内でリポジトリを接続できます。モデルは大幅に賢くなり、あなたのコードレビューも同様です。
CodeRabbitを始める - リポジトリを接続し、数分で最初のAIレビューを取得できます。クレジットカード登録は不要で、無料で試用開始できます。


