
CodeRabbitがClaude Marketplaceに登場!Learn more

Atsushi Nakatsugawa
June 30, 2026
2 min read
Claude Sonnet 5 review: Should you switch?の意訳です。
Anthropicが、ミドルレンジの最新モデルであるClaude Sonnet 5をリリースしました。この記事では、シンプルな問いに答えます。今使っているモデルにとどまるべきか、それともこのモデルに移るべきか。
Sonnet 5は突然現れたわけではありません。この1か月ほど、私たちはブログで新しいモデルを続けてレビューしてきました。
Sonnet 5には、Anthropicファミリーらしさがあります。辛抱強く、丁寧で、行動する前に問題を最後まで考え抜こうとします。
コードを書いて作る用途では、Sonnet 5はこの価格帯で私たちが使った中で最も高性能なモデルであり、素直に期待できるアップグレードです。一方、レビュー用途ではトレードオフがあります。よりきれいで鋭いコメントを生成する一方で、現在本番環境で使っている以前のモデルより検出できるバグは少なく、レビューあたりのコストも少し高くなります。
良い点は、その多くを調整できることです。そして多くのチームにとって、移行する価値は十分あります。Sonnet 5の新機能、コード作成とレビューでの性能、乗り換える意味があるかを順に見ていきます。
Sonnet 5は前のバージョンより深く考えます。ユーザーにとっては、古いモデルなら諦めていたような難しい問題にも取り組めるということです。
Sonnet 5には、思考の深さを調整するダイヤルがあり、不要な場合は段階的に下げてオフにもできます。これは予算を守るための機能です。見逃したバグの代償が大きい難しいレビューでは思考の深さを上げ、深い思考にコストをかけたくない定型作業では下げるかオフにします。
また、タスクの途中で自分の指示を書き換えることもできます。長いエージェント作業では、モデルが学習するにつれてゴールが変わりがちです。最初の計画に固定されたモデルは、もはや合わなくなった指示を押し進め続けます。Sonnet 5は代わりに自分の計画を更新するため、時間とトークンを消費しながら迷走するケースを減らせます。
セキュリティやサイバー関連の話題に対する新しい安全ガードレールも備えています。利点は、リスクのある出力が減ることです。一方で、正当なセキュリティ作業でもフィルターに引っかかることがあるため、その分野で使う場合はたまに拒否されることを想定しておく必要があります。

Sonnet 5を最もイメージしやすく言うなら、本当に動き、求められた水準で動作するコードをリリースすることに少しこだわりすぎる、中堅エンジニアのような存在です。その性質が、ほとんどの振る舞いを形作っています。私たちが何度も目にした習慣は次の4つです。
Sonnet 5のコード作成能力は、多くのチームにアップグレードを勧めたい最大の理由です。レビューの数値に入る前に、ゼロから何かを作るときにどう振る舞うのかを見ると理解しやすくなります。私たちは、日々行っている作業を渡しました。短時間で終わる機能から、明確な道筋のない難しい問題までです。
ある夜、私たちは難しいタスクを渡して昼食に出ました。その仕事では、モデルがコードを書き、そのコードでシミュレーションを実行し、結果ができるだけ良くなるまで出力を調整し続ける必要がありました。戻ってきたとき、終わっているか、詰まっているだろうと思っていました。どちらでもありませんでした。モデルはまだ動き続けており、私たちの指示追加なしに、自分で問題に取り組んでいました。
アプリケーション全体を自力で構築していました。長く動き続けた理由は単純です。たまたま動いた最初の答えではなく、より良い答えを追い求めていたため、何度も自分の解決策を磨き続けていたのです。以前なら、こうした振る舞いはより高価なモデルでしか見られませんでした。ミドルレンジのモデルがそれを行うのを見るのは、印象的な瞬間でした。
前述したこの粘り強さこそが、Sonnet 5が長く、終わりの見えにくい作業に強い理由です。1行の変更では気になる遅さが、ステップ数の決まっていない仕事では強みに変わります。シンプルなゴールをモデルに渡し、いくつかの方法を試してテストし、結果を自分で改善してから報告させるエージェントループに非常によく合います。
Anthropic自身の効果的なエージェント構築ガイドでは、これを評価ループと呼んでいます。モデルが結果を書き、その後にそれを批評し、改善するサイクルです。この種のワークフローを作っているなら、読む価値があります。Sonnet 5には、そのループが思考の仕方に組み込まれています。以前のモデルが話題から逸れたり諦めたりしたためにエージェント型コーディングを見送っていたなら、このリリースはその状況を変えるものです。
多くのモデルは、Sonnet 4.6も含め、テストを後回しの作業として扱います。Sonnet 5はテストを先に書き、その上に機能を構築し、完了したと思ったらすべてを実行する傾向があります。私たちが見た自己チェックは、この順序から直接生まれています。テストを実行しなければ、テストとコードの衝突は見つけられません。このモデルは常にテストを実行します。見た目は問題なさそうだったコードが1週間後に壊れた経験があるなら、その違いはすぐにわかるはずです。
Sonnet 5の手厚さは、ファイル数とトークン使用量に表れます。小さな依頼をしても、多くの成果物が返ってきます。追加のヘルパーや、機能本体より長いテストファイルを見ることになります。大きな機能なら、これは良いエンジニアリングに見えます。1行の変更では、自制しにくいモデルに見えます。
私たちの観測では、Sonnet 5はSonnet 4.6より遅くなりました。これは、おそらくSonnet 5が追加の思考を行うためです。時間と引き換えに丁寧さを得ることになり、長時間走らせる仕事では効果があります。一方、小さな変更を待っているときには負担に感じます。4.6が素早く答えを返す場面でも、5はより良い答えを求めて作業を続けます。小さな作業ほど、その違いを感じます。細かな点を2つ挙げると、4.6より多くのトークンを使い、明快ではあるものの少し説明が長めです。また、良い計画を書いた後、タスクの途中でそれを書き換える頻度が私たちの期待より高めです。どれも実装作業では致命的ではありませんが、小さな編集の山に向ける前に知っておく価値があります。
コードレビューを大規模に行うことが私たちの仕事なので、ここが最も重要な部分です。今ではAIが、多くのチームがリリースするコードの大きな割合を書いています。そして、そのコードには慎重な第二の目が必要です。470件のオープンソースPRを調べたところ、AIと共同作成されたPRには、人間だけのPRに比べて約1.7倍多くの問題が含まれていました。また、ある2025年の研究では、AIを積極的に使うチームでレビュー時間が91%増えたことがわかりました。レビューを行うモデルは、チームがどれだけ速くリリースできるかを左右する大きな要素になっています。
私たちはSonnet 5を評価基盤に追加し、既知のバグを含む固定のPRセットである標準ベンチマークにかけました。そして、いくつ検出できたか、コメントがどれだけきれいだったかを測定しました。こうしたレビューをどう構築しているかについては、AIコードレビューのためのコンテキストエンジニアリングの記事で詳しく説明しています。
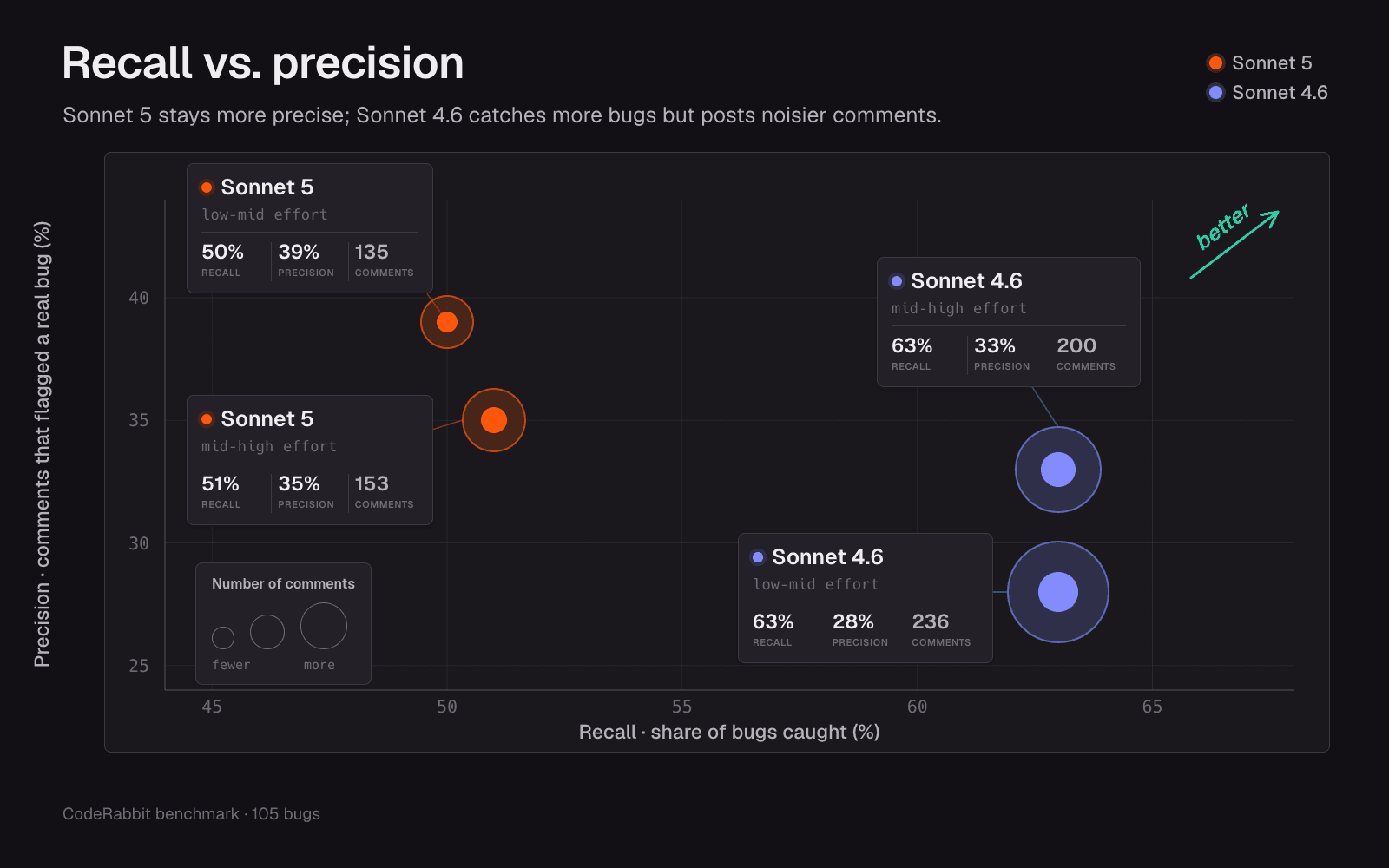
Sonnet 5のコメントはよりきれいで、指摘もノイズではなくバグである割合が高くなりました。私たちのベンチマークでは、適合率はSonnet 4.6の約29%から、およそ38〜40%まで上がりました。Sonnet 4.6は逆で、ほとんどすべてにコメントし、その中から残すべきものを選ぶ作業をユーザーに任せます。小さなことをすべて指摘するレビュー担当者を無効にしたことがあるなら、注意すべきものを強調することの重要性はすでにわかるはずです。
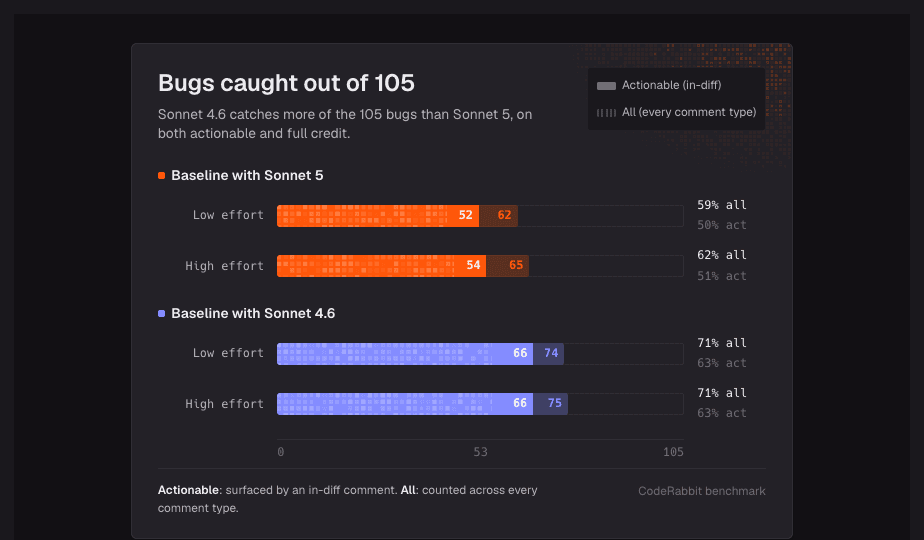
私たちのレビュー評価基盤では、Sonnet 5は現在の本番構成より検出できるバグが少なくなりました。厳密な「バグを見つけたか」という指標では、私たちのベースラインは約57%を検出し、Sonnet 5は50〜51%前後でした。意外だったのは、Sonnet 4.6がそれらのどちらよりも多く、約63%を検出したことです。ただし、4.6はよりノイズの多いレビュー担当者です。つまり、コメントで埋め尽くしてくるモデルが、見逃すバグは最も少なかったのです。Sonnet 5の思考の深さを上げる設定を強めてもスコアはほとんど動かず、コストはおおむね2倍になりました。より緩いスコア、つまりコメントの種類や表現のバリエーションを広く数える指標では、思考の深さを強める設定にすると検出数は現在のベースラインとほぼ同等に戻りましたが、明確に上回るところまでは行きませんでした。
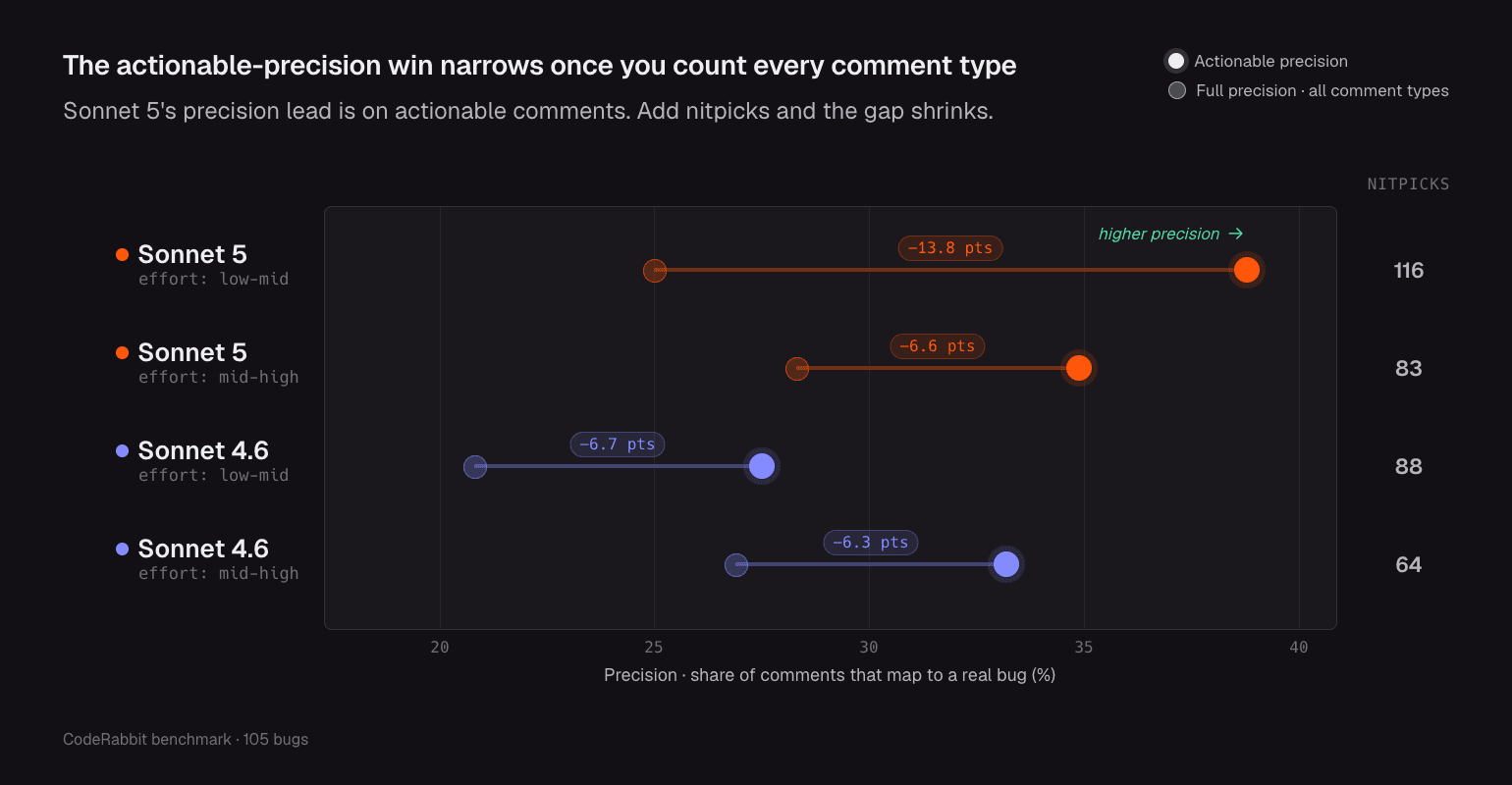
コメントの中には、少しノイズも隠れています。Sonnet 5は私たちのベースラインより3〜4倍多く細かな指摘を投稿し、思考の深さを強めた実行では、Sonnet 4.6よりも約80%多くなりました。最良のコメントはより読みやすい一方で、それを見つけるにはより多くの軽微な指摘を見分ける必要があります。思考をオフにした場合も試しました。一部の仕事ではベースラインに並び、別の仕事では少し下がりました。つまり、最重要コードでない限り、思考をオフにして安く実行してもほとんど失うものがない、軽めのレビュー作業があるということです。要点は、Sonnet 5が弱いレビュー担当者だということではありません。むしろ、より控えめで慎重なレビュー担当者です。レビューのノイズに苦しんでいるチームにとっては、そのほうが良いトレードオフになることがよくあります。
必要なのが生のカバレッジで、コメントを読み分ける余力があるならSonnet 4.6を選ぶべきです。より少なく、鋭いコメントと、コードを書く上でずっと頼れる相棒が欲しいならSonnet 5を選ぶべきです。Sonnet 4.6はもう少し多くのバグを見つけますが、Sonnet 5はあなたの注意力をずっと無駄にはしないでしょう。
チームが最も難しい仕事のために残しているOpusファミリーのようなフラッグシップモデルと比べると、Sonnet 5はレビュー品質でかなり近いところまで行きながら、コストは大幅に低くなります。安価なモデルでは十分でなかったという理由だけで、現在フラッグシップ料金を払っているなら、Sonnet 5は検討に値します。テスト中はトークン料金に注意してください。これだけ深く考えるモデルは、自分で節約分を食いつぶすことがあります。思考の深さを最大まで上げる設定は、今回の中で最も割に合いませんでした。コストはおおむね2倍になったのに、意味のあるほど多くのバグは見つかりませんでした。したがって、最上位設定をデフォルトにしないでください。Claude Opus 4.7がAIコードレビューに何を意味するかをレビューしたときにも、同じ傾向が見られました。
ほとんどのチームにとって、答えはClaude Sonnet 5です。Sonnet 5は、私たちがこのクラスで使った中で最も刺激的なコーディングモデルです。後で壊れるものを渡すより、数分余分にかけることを選ぶ慎重なチームメイトのように動きます。その性質により、本格的な開発作業をしている人にとって、4.6からの明確な進歩になっています。
平たく言えば、本格的なソフトウェアを書いたりリリースしたりしていて、自分の作業をテストし、難しい問題が解けるまで粘るモデルが欲しいなら、今すぐ乗り換えてよいでしょう。中程度の思考の深さで動かせば、最上位の価格を払わずに、利点の大半を得られます。また、純粋に品質のためだけにフラッグシップ料金を払っているなら、次の契約更新前にSonnet 5を現在のモデルと並べて試してください。わずかなコストで同等の仕事ができる可能性があります。
待つべきなのは、厳しいレイテンシ予算があり、小さな差分を大量に扱う高ボリュームのチームです。遅く慎重なスタイルが、まだ十分に見合わないワークフローだからです。
完璧ではありませんし、レビューで劣る部分については率直に述べてきました。それでも、コード作成とレビューにおける強みは、その弱点を十分に上回ります。アップグレードする理由を待っていたなら、これがその理由です。
AI生成コードの品質について全体像を知りたい方は、State of AI vs Human Code Generation reportを読み、チームがAI開発ツールをどう使っているかを確認するか、IDE内でCodeRabbitを無料で試してください。


