
CodeRabbitがClaude Marketplaceに登場!Claude Marketplaceの発表を読む発表を読む

Atsushi Nakatsugawa
May 19, 2026
1 min read
Explainable AI Code Reviews: Inside CodeRabbit’s Context Engineの意訳です。
CodeRabbitは、開発者と組織から信頼を寄せられる検証層であり、品質ゲートです。とはいえ、優れたレビューはバグを指摘したり修正案を出したりするだけのものではありません。優れたレビューは、変更を実装から意図まで遡って辿れるよう、チームを助けてくれます。何が変わったのか、なぜそれが重要なのか、どう良くできるのか、そしてリリースして安全かどうかを可視化してくれるのです。
開発者がコーディングエージェントへの依存を強めるにつれて、その仕事はどんどん難しくなっています。AIはすでにソフトウェアデリバリーの形を変えはじめています。10,000人以上の開発者を対象にしたFaros AIの調査によれば、AI活用が進んでいるチームでは、マージされるプルリクエストの数が98%増加している一方で、レビューに費やす時間も91%増えています。生み出されるコードが増え、デリバリーのペースが上がる中で、レビューはもはや「バグを捕まえる」だけの仕事ではありません。何が変わったのか、なぜそれが重要なのか、それがシステムの他の部分とどうつながるのかを、リリース前に理解するための、より良い手段がチームには必要です。
これこそが、説明可能性 (explainability)という考え方の核心です。当社CEOのHarjot Gillは、これを「エージェント時代におけるクラウドのオブザーバビリティに相当するもの」と表現しています。コーディングの仕事がAIエージェントへ移っていくほど、人間にはその出力を理解し、信頼するための新しいインターフェイスが必要になります。説明可能性は、新しいオブザーバビリティになりつつあるのです。自分たちのシステムやエージェントが何をしているのかを見て、理解し、検証できるようにするレイヤーということです。
最近、私たちはChange Stackをリリースしました。プルリクエストを、まるでシニアエンジニアが伴走するかのようにレビュアーへ案内してくれる、AIネイティブな新しいレビューインターフェイスです。CodeRabbitはこれまでも、サマリー、ウォークスルー、ロジック図、行動につながるレビューコメントを通じて、変更内容の理解を助けてきました。Change Stackは、その土台の上に「変更を辿る道筋」を提示するものです。単に何が変わったかではなく、各ピース同士がどうつながっているのかまで見せてくれます。
開発者が手で書くコードを減らし、生成をエージェントに任せる比率が増えるにつれて、レビューの問いは「この差分は正しいか?」から「私たちが意図したものを、このシステムは実際に作ったのか?」へとシフトします。私たちはこれを意図のレビューと呼んでいます。キーストロークそのものではなく、計画とその結果を検証することです。
差分(diff)は、20年近くにわたってレビューのデフォルトのインターフェイスでした。CodeRabbit Reviewは、システムが「変更の形」を説明できるようになったときに、何が可能になるかを示すものです。開発者は、自分の意図と変更が一致しているかをそこで検証できます。
たとえば、CodeRabbitはセマンティック差分(semantic diff)を使ってPRをレビューします。従来の行単位の差分では、変数のリネームやフォーマット修正、ロジック変更が、すべて同じ一覧の中に並んでいます。その結果、シグナルとノイズを切り分ける作業がレビュアーに丸投げされてしまうのです。
セマンティック差分は、変更の構造を理解します。関係のない変更を取り除き、移動しただけのコードを検出し、意味のある変更だけを浮上させます。レビュアーは実際に何が変わったかだけを見られるので、より速く、より正確にコードレビューを進められます。こうした体験が可能になるのは、その下にあるより深いシステムのおかげです。意図を理解し、ファイルをまたいだ変更同士をつなぎ、影響範囲を推論し、プルリクエストを通る筋道を説明する、コンテキストエンジニアリングです。
CodeRabbitにおいて、信頼できて説明可能なレビューは、レビューコメントが書き出されるよりもずっと前から始まっています。
すべてのPRについて、私たちはモデルが正確に推論できるようなコンテキストを構築します。リポジトリをクローンして差分を分析し、その変更がコードベース全体(ファイル横断、リポジトリ横断)とどう結びついているかを辿れるコードグラフを組み立てます。その上でコンテキストエンジンは、周辺のエンジニアリング上の知識を取り込みます。関連Issue、アーキテクチャの基準、独自のレビュー指示、コーディング規約、過去のPR、チーム固有のLearnings、そしてMCPを通じて、チームが日々向き合っているドキュメントやシステムまでです。最後に、そのすべてを「今回の変更にとって本当に関連するもの」へと絞り込みます。
そこに並走する形で、40以上のリンターやSASTツールからのシグナルが流れ込みます。リアルタイムのウェブ検索が、最新のリリースノートや、新たに公開された脆弱性情報を引き寄せます。そして、これらすべては一時的に作られた、隔離されたサンドボックスの中で動き、データの保持は一切ありません。
これこそが、レビューの背後で行われている本当の仕事です。私たちのシステムでは、コンテキストの拡充に多くの労力を割いています。難しいのは、LLMに差分のレビューを依頼することではありません。難しいのは、モデルが意図を理解し、影響範囲を推論し、自分の気付きをきちんと説明できるよう、正しいコンテキストを、正しい順序で、正しい粒度で渡してあげることです。
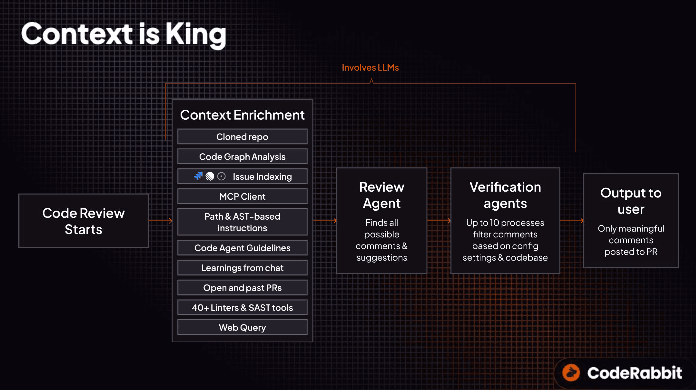
コンテキストエンジンの周りに組まれた「ハーネス」も、同じくらい重要です。ハーネスは、それぞれのタスクを複雑さに応じて適切なモデルへ振り分けます。深い推論を必要としない部分では安価で速いモデルへ、深い推論が必要な場面ではフロンティアモデルへ、そして当社の品質基準を満たすときにはオープンモデルへ、という具合です。レビューエージェントが候補となるコメントを上げ、検証エージェントがそれらをコードのガイドライン、設定、チームの好みに照らしてフィルタリングし、最終的にレビューコメントが開発者の元に届きます。そしてその下層には、モデルの新バージョン、プロンプトの変更、コンテキスト戦略の変更を、再現率、適合率、レイテンシ、コストの観点から毎回テストする評価フレームワークが据えられています。このフィードバックループがあるからこそ、私たちは「とりあえずトークンを増やす」ことに頼らずに品質を伸ばせます。
これは「システム周辺のシステム」だと言えます。コンテキストの取得、ランキング、フィルタリング、サンドボックス化、ツールのオーケストレーション、プロンプト設計、モデルのルーティング、検証、評価ループのすべてが連携して動いています。
CodeRabbitは、何百万件ものプルリクエストと15,000を超えるエンジニアリングチームに対して、3年間にわたってこのハーネスを磨いてきました。「どんな変更にはどんなコンテキストが効くか」という、積み上げてきたドメイン知識こそが、差分を要約するだけのシステムと、リリースしたかったものを台無しにしかねない問題まで見つけ出せるシステムとの差を生んでいるのです。
AIはコードを書くことができますが、リリースされる成果物に対する責任は、依然としてあなたのチームにあります。CodeRabbitは、コントロールを失わずにスピードを保つための「AIネイティブな品質ゲート」です。すべての変更について即時に説明を提供し、プルリクエストごとに一貫した基準を効かせるため、リリースされる成果物が、意図したものと一致した状態になります。
次に大きめのPRがあなたのキューに上がってきたら、ぜひChange Stackを試してみてください。Change Stackは、いま期間限定で、すべてのCodeRabbitユーザーが無料で利用できます。CodeRabbitのPRサマリーコメント内にある Review Change Stack をクリックするだけです。


