Atsushi Nakatsugawa
June 09, 2026
2 min read
Claude Fable 5 Model Reviewの意訳です。
Fable 5は、自律的なコーディング作業で試す価値があります。特にプロンプトが不完全で、エージェントがビルド前に環境を把握する必要がある場面に向いています。本番環境のコードレビューでは、現時点では現在のベースラインとOpus 4.8の方が安全に見えます。
Fable 5は、タスクの指定が不十分なときに、エージェントの振る舞いを変えるタイプのモデルです。探索の進め方がうまく、まず環境を理解し、次に利用可能なファイルやツール、制約を特定し、そのうえで根拠のある全体像から構築に入ります。これから何をするかを長々と説明することはあまりありません。十分なコンテキストがあれば、すぐに作り始めます。
この傾向は、モデルの能力をテストするために使った複数のコーディングプロジェクトで確認できました。Fable 5には曖昧なプロンプトを与えても、プロトタイプの外枠ではなく、完成度のあるプロジェクトが返ってきました。また、以前のモデルレビューではより細かな誘導なしでは到達しづらかった、あまり自明ではない解決経路も見つけていました。
ただし、同じ振る舞いにはコストも伴います。私たちのコーディングタスクベンチマークでは、Fable 5はハーネスによって打ち切られるまで作業を続けることがよくありました。このため、モデルは有能に感じられる一方で、強い停止ルールを持たないエージェントワークフローでは高コストで遅くなります。
そのため、推奨は単純にすべてを切り替えることではありません。自律性そのものがプロダクト価値になる場面ではFable 5を使い、精度とコメント量の調整が進むまでは、現在のコードレビューパスを維持する、という判断です。
探索、計画、構築が仕事の中心であり、より徹底した実装のために時間がかかってもよい場合はFable 5を使います。現時点では、現在のレビュアーは維持します。コードレビューのシグナルはカバレッジ面では近いものの、デフォルトにするには精度や量の面でまだ十分ではありません。
Fable 5は、自律的なナレッジワークとコーディング向けのMythosクラスモデルとして位置づけられています。これは、通常のモデルアップグレードとは異なる評価基準を求めるものです。価値は、単に回答がよくなることや、Opus 4.8より速くなることではありません。より長く動くエージェント作業に向けて作られたモデルであり、より多くのコンテキストを保持し、計画を立て、人間の介入が必要になる前にタスクをさらに先まで進めることにあります。
リリース時の制約も、能力を理解するうえで重要です。このモデルには、一部のサイバーセキュリティおよび生物学関連のリクエストを遮断する分類モデルが含まれています。また、分類モデルによるブロック後に、オプトインでOpus 4.8へフォールバックする機能もサポートされています。開発者にとっての要点は単純です。深さが必要なタスクではFable 5を使い、予測しやすい速度や精度が必要なワークフローでは既存の経路を維持する、ということです。
リリース概要にある公開価格は、入力100万トークンあたり10ドル、出力100万トークンあたり50ドルで、リージョナルエンドポイントには10%の追加料金があります。推論モデルでは、特に新しいモデルカテゴリが導入されるときに、このような価格を見てきました。今後のイテレーションでコストが下がる可能性はありますが、初期段階での見方は明確です。開発者はFable 5を、単なるトークン単価ではなく、解決できたタスクあたりのコストで評価すべきです。
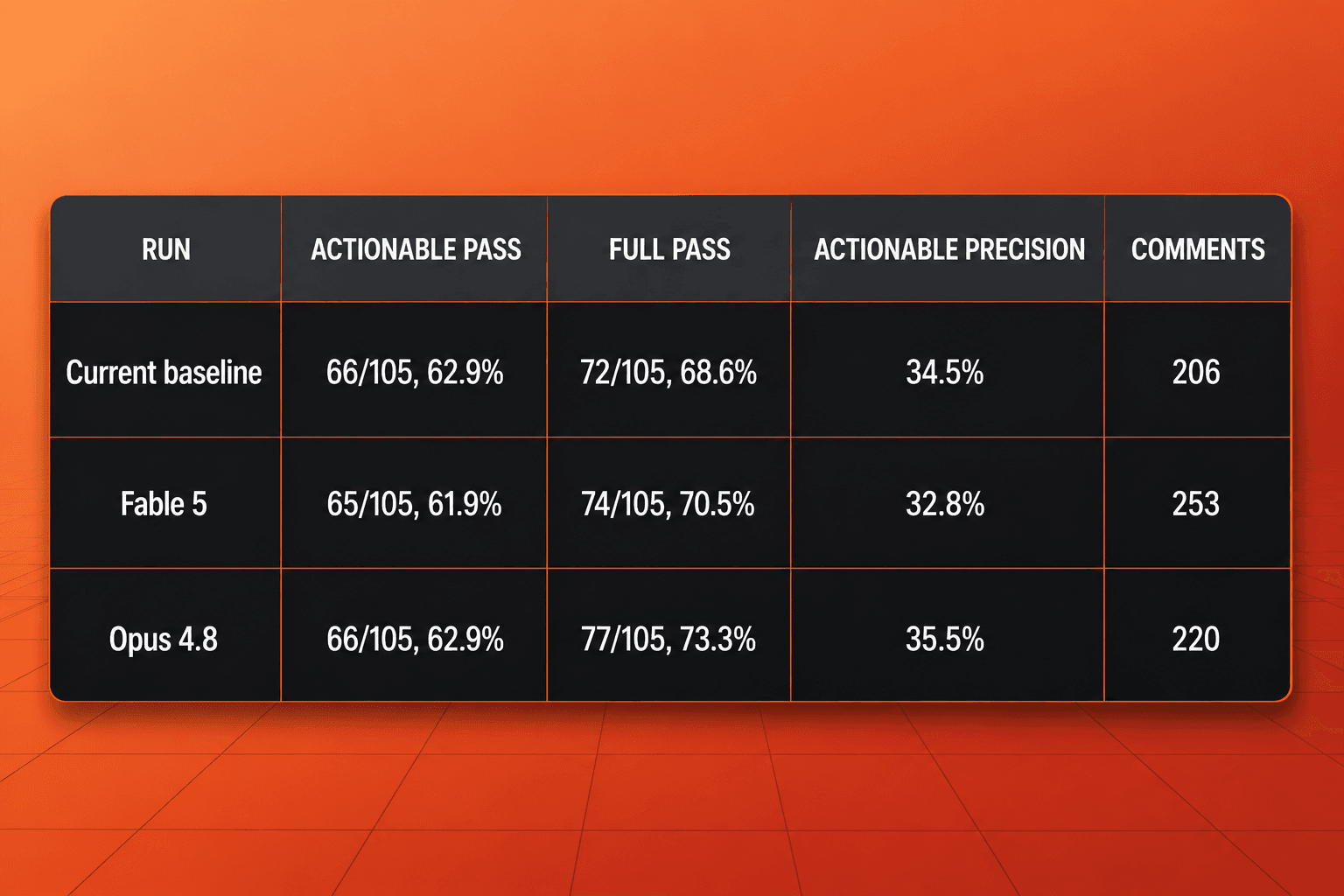
105件のEPコードレビューベンチマークでは、Fable 5は検出カバレッジで現在のベースラインに近い結果を残しました。アクション可能なEPは105件中65件をパスし、現在のベースラインとOpus 4.8の105件中66件をわずかに下回りました。すべてのコメントタイプを数えると、Fable 5はフルEPパスで105件中74件となり、ベースラインの105件中72件をわずかに上回りました。
弱かったのは精度です。Fable 5のアクション可能な精度は32.8%、フル精度は19.4%でした。一方、Opus 4.8はそれぞれ35.5%、26.5%に達しています。また、Fable 5は253件のコメントを生成しており、比較対象のどちらよりも多く、断定的なコメントやnitpick系の出力が大きく増えていました。この組み合わせはコードレビューでは重要です。ノイズの多いコメントは、カバレッジが競争力を持っていても、レビュアーの作業を増やすからです。
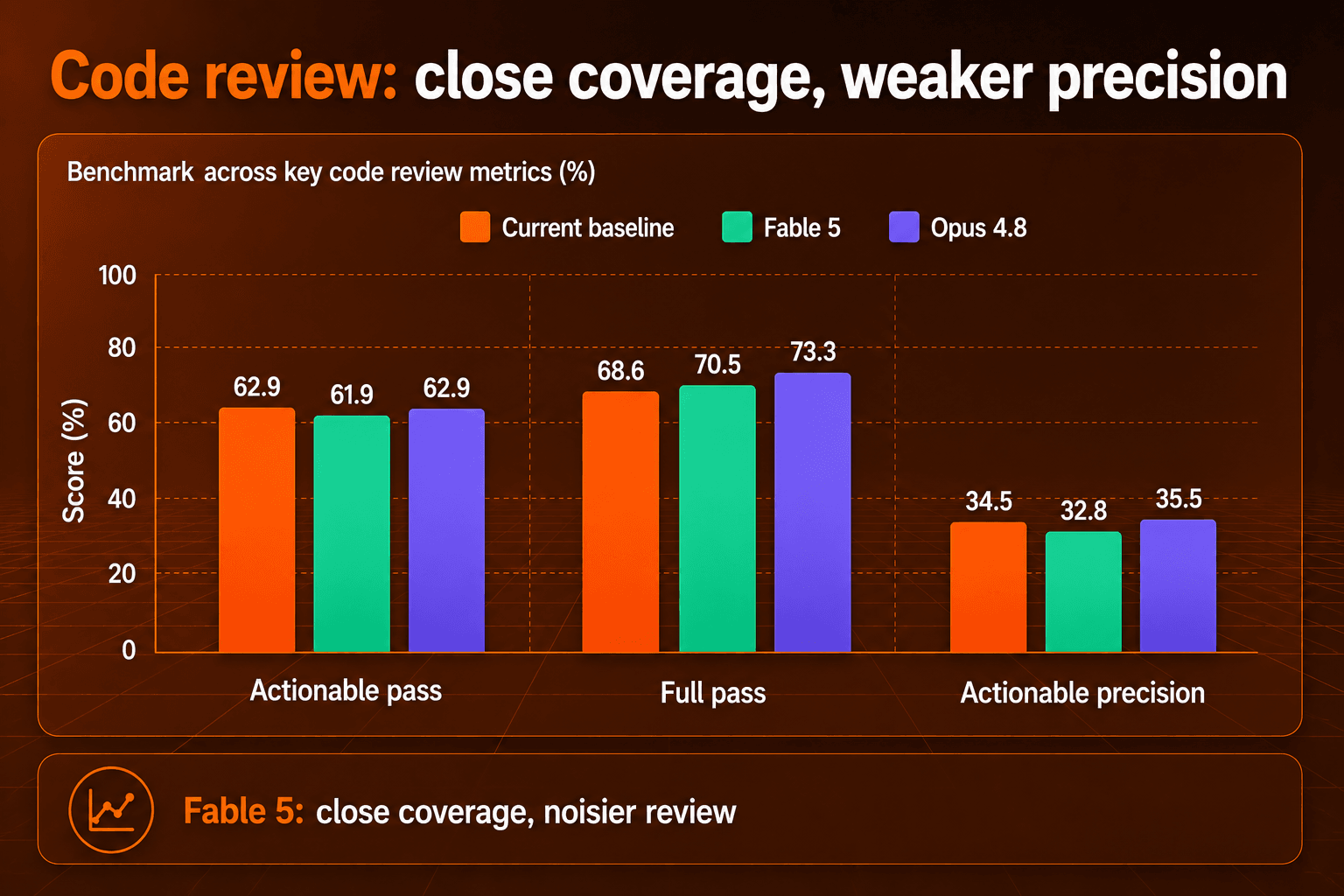
カテゴリ別の内訳を見ると、見出し上のカバレッジ数値が示すよりも結果は不均一に感じられます。Fable 5には有用な広さがありますが、開発者がレビュアーに期待する種類の問題全体で、一貫して改善しているわけではありません。運用上、チームは有益な指摘を期待できる一方で、レビューへの信頼を得るのが難しいカテゴリについては、手動トリアージとフォールバックのカバレッジが引き続き必要になります。
難しい例を見ると、展開判断はより慎重になります。難易度4のEPでは、Fable 5は16件中8件をパスしました。ベースラインは16件中10件、Opus 4.8は16件中9件です。これはFable 5がレビュアーとして低品質という意味ではありません。ただし、レビューへの信頼を獲得するのが最も難しいケースでは、開発者がより多くの人間の判断を必要とすることを意味します。
開発者は、Fable 5を汎用的なコーディングモデルよりもセキュリティを意識しているモデルとして捉える可能性があります。特に、リスクのある振る舞いに対して慎重な実装を求めるタスクではそうです。ただし、これをそのままセキュリティレビュアーとして扱うべきではありません。現実的な姿勢としては、より深いセキュリティ重視のコーディング作業に使い、その後も指摘を信頼する前にレビュー基準を高く保つことです。
最も強いセキュリティシグナルは、能動的な実装から得られました。私たちのコーディングタスクベンチマークでは、明確な目的があり、コードを読み解くための十分な時間がある場合、Fable 5はセキュリティ関連のBanditタスクを完了しました。Fable 5は、レビューですべての問題を検出するよう求められる場合よりも、具体的なコーディングタスクの一部としてセキュリティに取り組む場合の方が有用に見えます。
明確なパターンが見えたため、私たちはコーディングタスクベンチマークを途中で止めました。Fable 5は有意義な進捗を出せる一方で、多くのタスクがエージェントのタイムアウトに達するほど長く実行されました。そのため、このセクションは最終的なリーダーボードスコアではなく、体験面のシグナルです。重要なのは、タスクが拡大し続けるときに、モデルが現実のコーディング作業でどのように振る舞うかです。
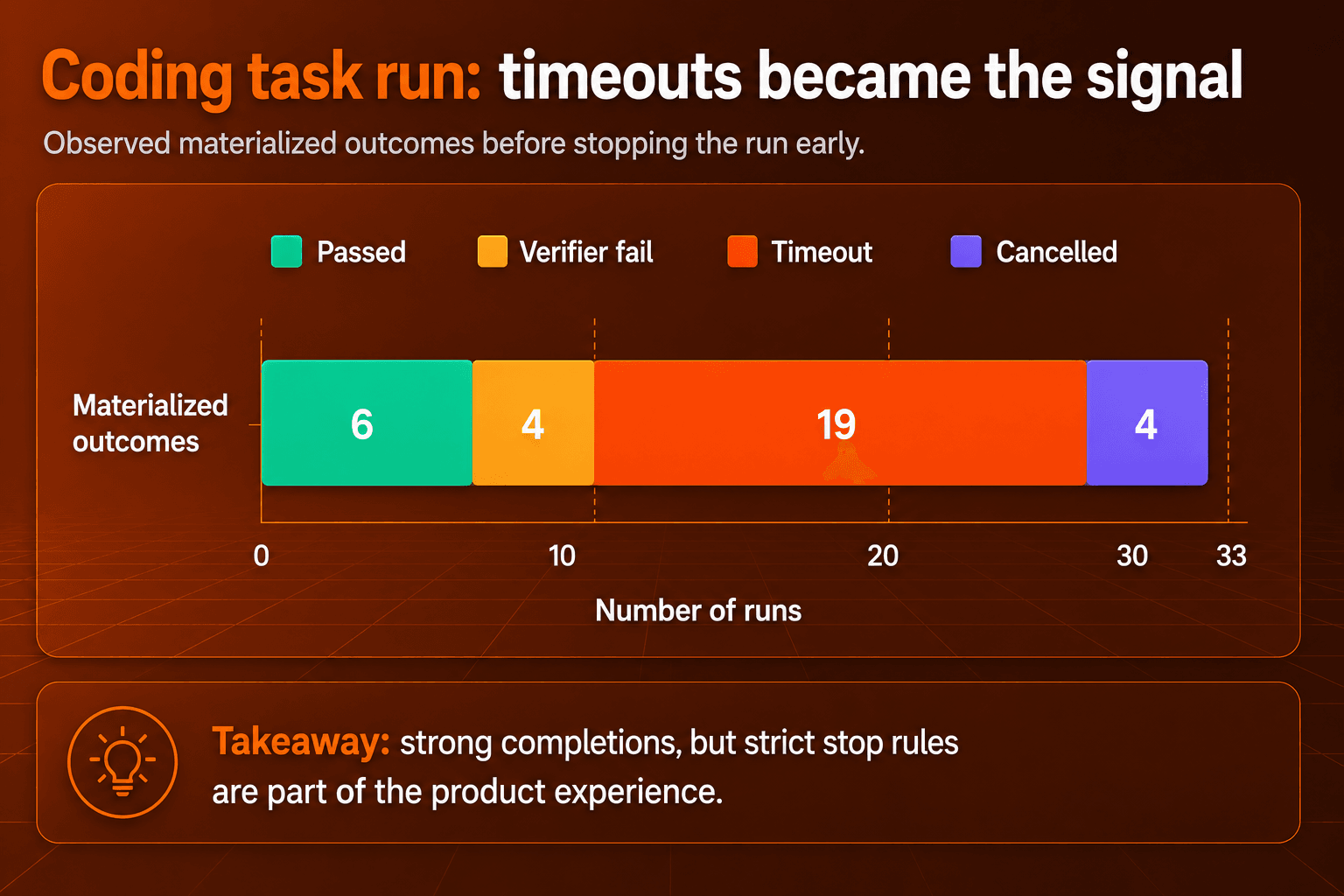
この結果の内訳は、完了済みベンチマークスコアではなく、エージェントの振る舞いに関するシグナルとして読むべきです。
このシグナルには両面があります。Fable 5がタスクを完了したときは、浅い編集ではなく、本格的なパッチを生成しました。一方で苦戦した際には、ハーネスが支えられる範囲を超えて探索を続けました。開発者にとっては、時間、ステップ数、トークンに明確な上限を設定できるなら、待つ価値がある深い作業に向いたモデルだということです。
完了したタスクからは、Fable 5が最も有用な領域も見えてきます。成功したのは型、API、公開動作、クエリロジック、キャッシュ、セキュリティ関連コードなど、現実的な構造を持つ実装作業でした。失敗例にも価値がありました。すぐに間違った方向へ進んだものもあれば、収束しないまま相当な努力を投入したものもあります。開発者が計画すべきトレードオフは、より深い作業が可能になる一方で、常にきれいに完了するわけではない、という点です。
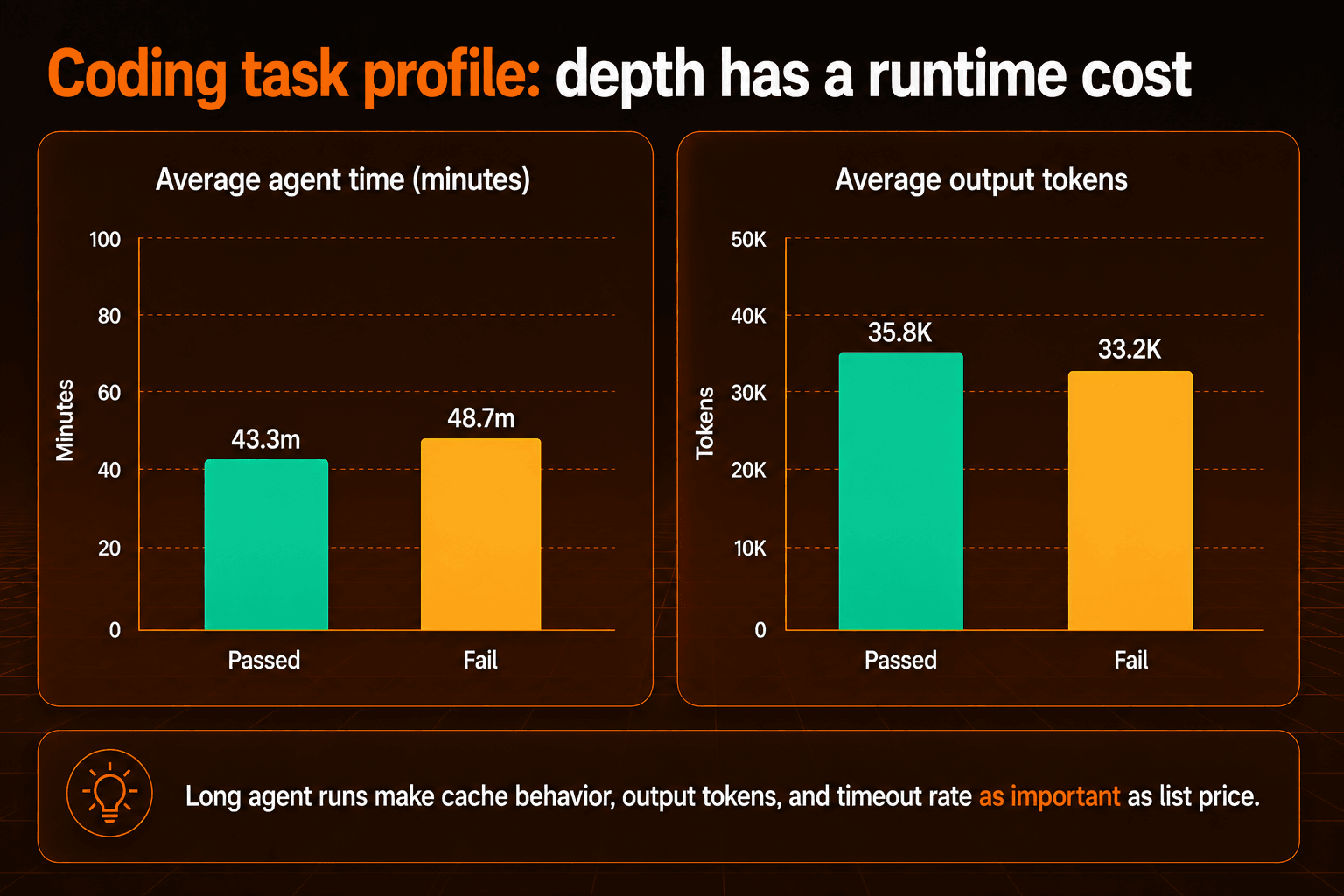
Fable 5は、完了時にも相応の時間と出力予算を使います。タイムアウトした場合でも、ハーネスは相当なコンテキストを消費する可能性があります。
トークンプロファイルも、時間データと同じことを示しています。Fable 5のコストが高くなるのは、単にリスト価格のためだけではありません。答えに到達する前に、より長く考え、探索し、生成することもあります。キャッシュ割引によって最終的な請求額が下がる可能性はあり、今後のイテレーションで価格が下がる可能性もあります。それでもチームは、解決できたタスクあたりのコストでモデルを評価すべきです。この種のエージェント作業では、公開されているトークン価格と同じくらい、タイムアウト率、キャッシュの振る舞い、出力トークン使用量が重要になります。
コーディングプロジェクトでは、Fable 5が最もよく機能する場面が最も明確に見えました。あるプロジェクトでは、モデルは動作する表面を組み立てるだけではありませんでした。状態や意思決定、レンダリング、コントロールを別々のレイヤーに分けて実装を整理し、そのうえでビルドに成功する成果物を作りました。残っていた課題は、最初の完成版に期待される種類のものでした。より堅牢なテストカバレッジ、より安全な状態管理、不正な入力に対するより厳密なガードです。
別のプロジェクトでも、よりインタラクティブな設定で同じパターンが見られました。Fable 5は、安定したループ、手続き的なビジュアル、状態を持つインタラクション、フェーズ変化、キャンバス効果、複数のアプリ状態、成功する本番ビルドを備えたリアルタイムアプリケーションを構築しました。問題は基本的な完了失敗ではありませんでした。次のレイヤーのエンジニアリング作業、つまり決定的なテスト、小さい画面向けの調整、状態のエッジケースでした。
これが、以前のモデルレビューとの最も明確な定性的差分です。十分なコンテキストがあれば、Fable 5は計画を過剰に説明したり、何度も許可を求めたりするのではなく、直接実装に入ります。また、より狭いコード補完モデルよりも、アーキテクチャ、インタラクション、プロダクトの形に多くの労力を使っているように見えます。推奨されるのは、選択的な採用です。Fable 5は、自律的なコーディング作業で試す価値があります。特に、より深い計画、複数ファイルにまたがる実行、実装に追加の時間をかけることが有効なタスクに向いています。現時点では、本番のコードレビューのデフォルトにはしません。
コードレビューでは、Fable 5が精度とコメント量の面で改善するまで、現在のベースラインまたはOpus 4.8の経路をデフォルトとして維持します。コーディングエージェントでは、特に探索とより深い実装が有効な作業において、Fable 5はより魅力的です。ガードレールは運用面にあり、明確な予算と停止条件、レビューチェックポイントを与えることです。セキュリティワークフローでは、よりよいセキュリティレビューの証拠としてではなく、セキュリティを意識した実装に有用なものとして位置づけるべきです。