

Atsushi Nakatsugawa
June 16, 2026
1 min read
Out with Tokenmaxxing. In with Mergemaxxingの意訳です。
トークン価格は2022年末から98%下落した一方で、企業のAI請求額は3倍になりました。TechCrunchによれば、Uberは2026年のAIコーディング予算を4月までに使い切りました。Gartnerは、従量課金型のAIコーディングツールを利用する企業の40%が、2027年までに想定予算の2倍を超える予期しないコストに直面し、体系的なコスト監視と最適化戦略への需要が高まると予測しています。しばらくの間、業界はトークン消費量を、意欲の代替指標のように扱ってきました。エージェントが多く消費するほど「AIに積極的」だと見なされていたのです。
この考え方には欠陥があります。トークンは入力であり、成果ではないからです。ここにはグッドハートの法則が当てはまります。トークン消費量が目標になった瞬間、それは有効性を測る指標として役に立たなくなります。業界は以前、開発者の生産性を測る指標としてコード行数を使ったときにも、同じ教訓を学びました。今、企業はそれをトークンで学び直しており、焦点は費やした1ドルあたりの成果を測る方向へ移っています。
この問題が最も重要になるのが、AIコードレビューです。あなたが買っている成果は、トークン最大化ではありません。高品質なコードが、自信を持ってマージされ、リリースされることです。つまり、選ぶべきシステムは、私たちがMergemaxxing、つまりマージ最大化と呼ぶものに最適化されているべきです。品質やコストを犠牲にせず、プルリクエストのマージ速度を最大化することです。多くのシステムは、品質とコストを同時に最適化するようには作られていません。
AIコードレビューにおける1つのアプローチは、トークン消費を最大化することで品質を最適化することです。たとえば、リリース当初、CursorのBugbotは、ノイズを除去するために多数決を使い、すべてのPRに対して8つの並列レビューパスを実行していました。現在は完全にエージェント的な設計になっており、モデルが「どこを深掘りするかを決め」、実行時に必要なコンテキストを何でも取り込みます。そして「疑わしいパターンはすべて調査する」よう促すプロンプトによって制御されています。
その記事では、品質指標を少しずつ高める40の実験が詳しく説明されています。しかし、トークンコストには一切触れていません。言い換えると、賢く解くのではなく、より大きな計算資源を投入することを選んでいるのです。
このアプローチは機能し、精度の高いレビューを生みます。しかし、エージェントが探索量を決める場合、各レビューのコストはしばしば上限がありません。
CursorのBugbotは最近、従量課金を始めました。PRのサイズと複雑さに応じて、1回あたり1.00〜1.50ドルが請求されます。あるコミュニティメンバーは、PRあたり7〜10.50ドルになると見積もっています。月に15〜20件のPRを出す開発者なら、1ユーザーあたり月額105〜210ドルです。その非効率は、ユーザーに転嫁されます。
もう1つの一般的なアプローチは、汎用の最先端コーディングエージェントをPRに向けることです。そのハーネスは、機能の実装、スプレッドシートの作成、ドキュメントの下書きなど、何でもできるように作られています。コードレビューでは、その柔軟性がオーバーヘッドになります。目的特化のレビュアーならすでに知っているコンテキストを再発見するために、システムは大量のトークンを消費します。
その結果、高額でありながら、検出されるバグが少ない可能性のあるレビューになります。その例が、コードレビューにClaude Code Reviewを使うケースです。これはPRあたり平均15〜25ドルで、トークン使用量に基づいて請求され、PRの複雑さに応じて増えます。一般的な開発速度では、1ユーザーあたり月額225〜500ドルになります。そして、インセンティブ構造にも注目すべきです。ベンダーがトークン単位で請求する場合、ハーネスが消費するすべてのトークンは収益になります。
こうしたツールの隠れたコストは行動に現れ、時間がたつにつれて品質問題になります。レビューが従量制になると、支出管理が品質管理になります。これらのツールでは、多くの場合、レビューをいつ起動するか、どの頻度で実行するか、レビュアーにどれだけの労力をかけさせるかをチームが設定できます。
しかし、請求額を管理するためにレビューの挙動を調整し始めた瞬間、どのコードを精査するかも決めていることになります。チームは「重要度の高い」PRだけをレビューし、修正後の再レビューを省き、もう一度イテレーションを積む前に考え込むかもしれません。
これは、スキップしたレビューのすべてがバグを本番環境へ持ち込むという意味ではありません。しかし、修正コストが最も安い早い段階で検出される問題は少なくなります。レビューを配給制にすると、そのコストは下流へ、つまり欠陥の修正がより難しく高くつく本番環境の近くへ押し出されます。
私たちは、チームが品質とコストのどちらかを選ばなければならないとは考えていません。よく作られたレビューシステムは、その両方を提供し、効率的で正確であるべきです。モデルのコンテキストウィンドウに含まれる不要なトークンは、すべて注意を薄め、本当のバグを見落とす確率を上げます。システムから無駄を取り除く規律は、レビューを正確にする規律でもあります。
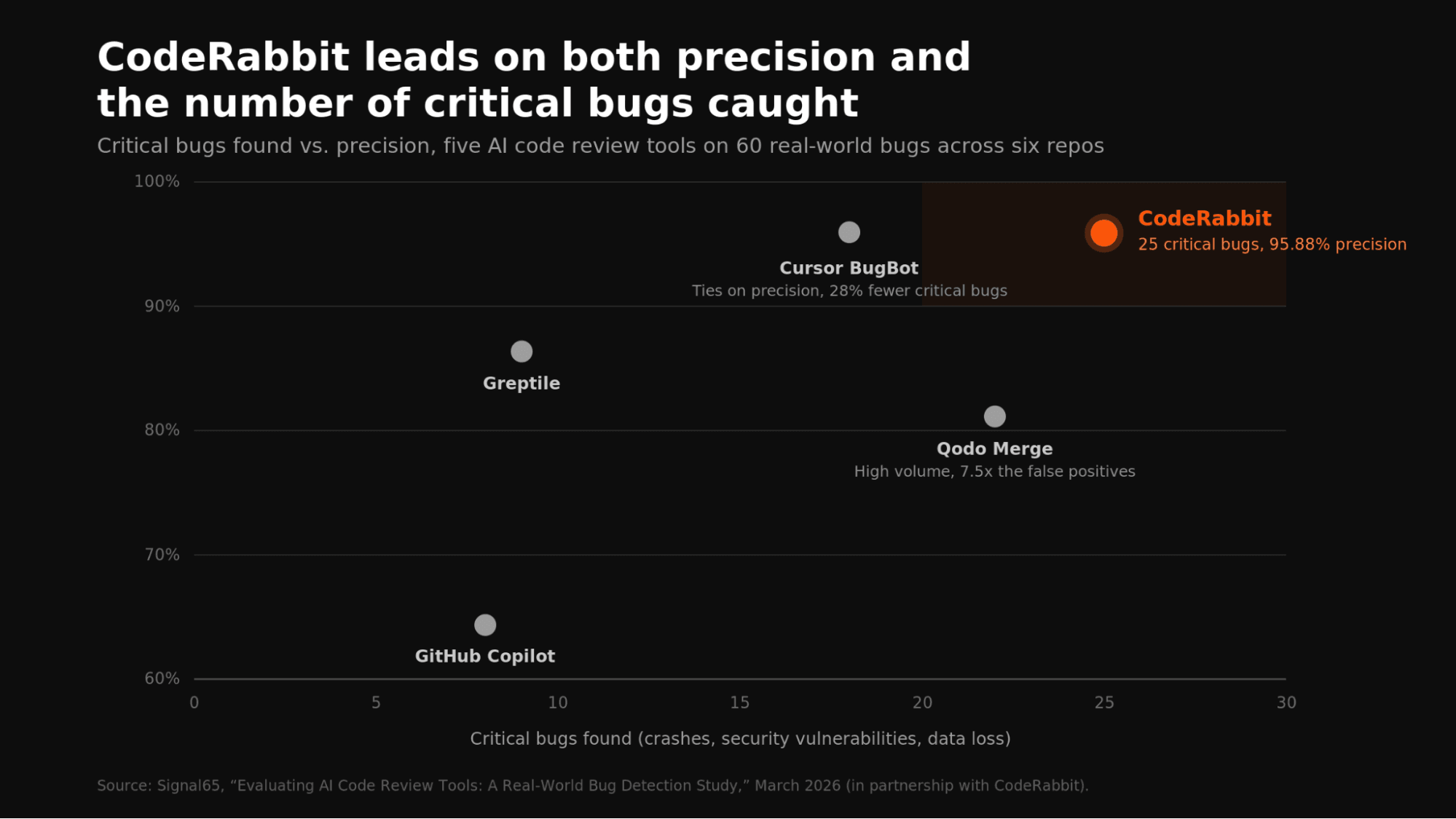
Signal65によるハンズオン評価では、5つのAIレビューツールを、6つのオープンソースリポジトリにある過去の本物のバグに対してテストしました。その中でCodeRabbitは、クラッシュ、セキュリティ脆弱性、データ損失といった最も重大なバグを95.88%の精度で見つけました。両方の指標で同時に首位に立った唯一のツールでした。精度で最も近い競合は、見つけた重大バグが28%少ない結果でした。Martianの評価でも同じ傾向が示されています。CodeRabbitはF1スコアで首位であり、コードレビューでさらに重要な再現率、つまりシステムが本物の問題をどれだけ捕捉できるかという指標でも優れています。
すべてのPRが同じ水準のレビューを受けるため、チームは自信を持ってマージし、リリースできます。その裏側では、2つのアプローチ(トークン最適化とコスト最適化)と、3つの主要技術(コンテキスト規律、Smart LLM Routing、Prompt Caching)が連携して、その成果を生み出しています。

より良いレビューは、より適切に選ばれたコンテキストから生まれます。これはコンテキスト規律と呼ばれ、コンテキストエンジニアリングの一部です。CodeRabbitはこの技術をコンテキストエンジンに組み込み、無関係な情報でLLMを圧倒したり、レビューの精度を高める重要なコンテキストを欠落させたりしないようにしています。
すべてのレイヤーでの蒸留。 コードグラフ、MCP連携、ドキュメント、コーディングガイドライン、学習内容、静的解析結果など、すべてのコンテキストソースは処理レイヤーを通ります。そこで、対象PRに関係するものだけが抽出されます。CodeRabbitは、レビュアーにより良いコンテキストを渡すために、入力トークンの大半を意図的にこのエンリッチメント段階で使います。PRが呼び出す関数は数百行に及ぶかもしれませんが、レビューエージェントに必要なのは、その関数が何をするのかを正確に要約したものだけかもしれません。
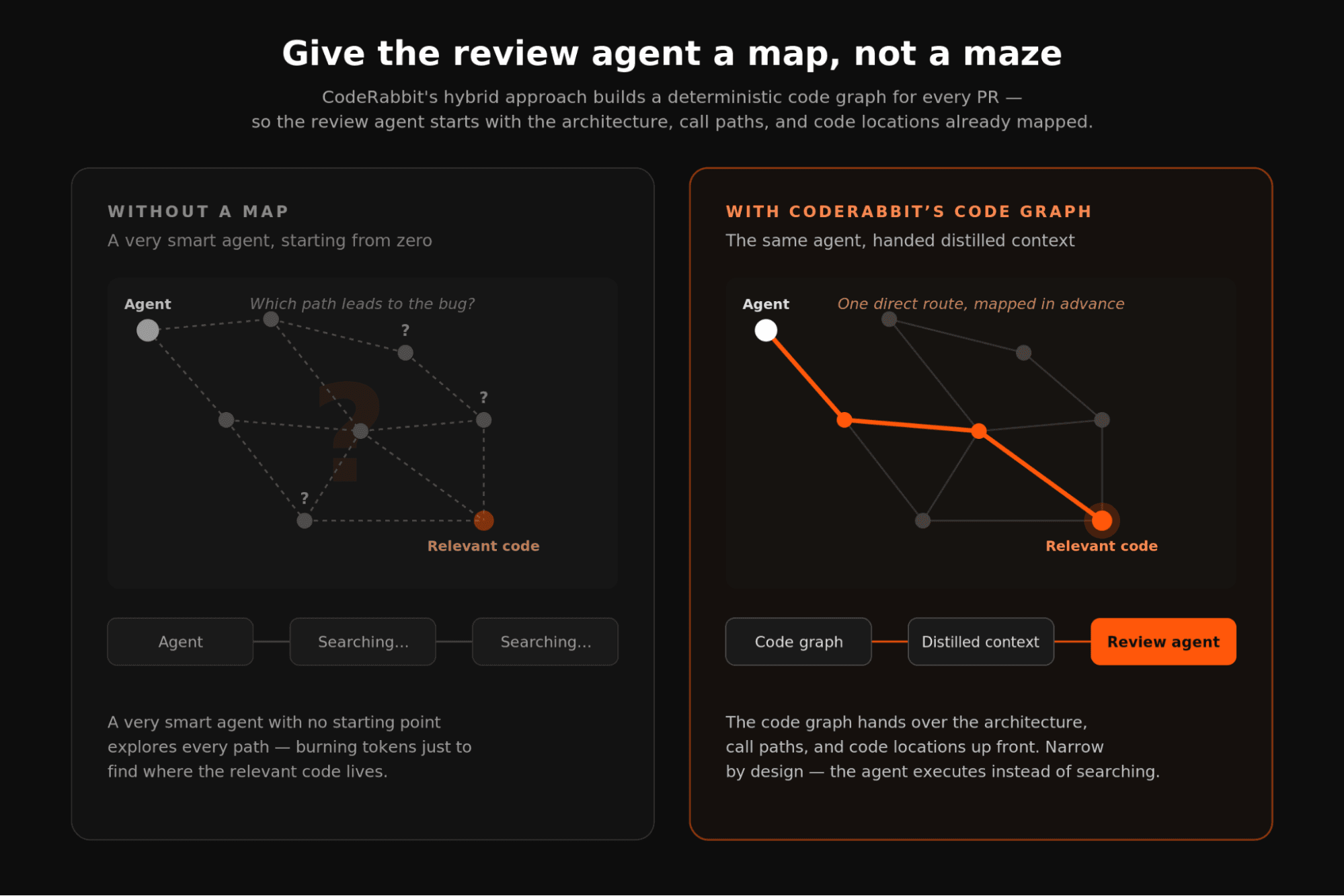
オープンエンドな探索ではなく、ドメイン知識。 CodeRabbitでは、経験豊富なエンジニアのようにレビューへ向き合います。優れたレビュアーが推論を始める前に必要とする基本的なシグナルを、私たちは知っています。そのため、その発見作業をすべてエージェント任せにはしません。
CodeRabbitは、コードレビューにハイブリッドAIアプローチを使い、決定的な解析とエージェント的な推論を組み合わせています。すべてのPRについて決定的なコードグラフを構築するため、エージェント的な手順が始まる頃には、エージェントはすでにアーキテクチャ、呼び出し経路、関連コードの場所を理解しています。探索経路は設計上狭くなっています。どこから始めるべきかを伝えるため、見つけ方を探すために余分なトークンを使う必要がないのです。
コスト最適化とは、品質を落とさずに、残りのすべてのトークンをできるだけ安くすることです。
スマートなLLMルーティング CodeRabbitには、各モデルがシステムをどこで改善するのか、どこで単にコストを増やすだけなのか、どこで小さなモデルの方がうまく仕事をこなせるのかを理解するために、モデルを継続的に評価しベンチマークする専任のエンジニアリングチームがあります。
コンパクトなモデルは蒸留を担当し、最大規模の多段階推論モデルは、深い分析が効果を発揮するレビューエージェントのために確保されます。大きなモデルが必ずしも優れているわけではありません。そのレベルの推論を必要としないタスクでは、レイテンシ、ノイズ、不要な複雑さを増やすことがあります。タスクごとのルーティングにより、システムの各部分を、それぞれが最も適した作業に合わせられるため、効率とレビュー品質の両方が向上します。
プロンプトキャッシングを使ったインテリジェントな差分レビュー CodeRabbitは、すべてのフォローアップレビューを差分として扱います。変更されていないコードは最初からレビューし直さず、長いプロンプトの安定した部分は、反復のたびに提示するのではなくキャッシュできます。これはプロンプトキャッシングとも呼ばれ、レビュアーの注意、推論、トークンを、本当に変わった部分に集中させます。
トークンとコストの最適化は、顧客へ還元されます。多くのチームは自前のAIレビューシステムを作るところから始めますが、特にレビュー処理の各タスクで最先端モデルを使う場合、トークン支出がどれほど急速に積み上がるかに気づいていません。小規模チームでも、トークンだけで月に数千ドルをすでに使っており、そのアプローチはスケールしないと話す顧客もいます。
トークンコストは問題の一部にすぎません。モデルルーティング、コンテキスト蒸留、ベンチマーク、新しいモデルリリースへの追従には、専門性とインフラが必要です。多くのチームには、それらを構築するための知識や時間がありません。CodeRabbitはその複雑さを引き受け、顧客にとってのビジネス価値へ変換します。
AI担当VPのDavid Lokerによる社内実験では、ドメイン知識もコンテキストエンジニアリングもないシンプルなレビューシステムを作りました。そのシステムは、1つのバグを見つけるためにおよそ20万トークンを消費しました。ドメインに基づく少しの最適化を加えると、更新後のバージョンは合計約1万8000トークンで同じバグを見つけました。内訳はdiff自体に約1万7000トークン、対象を絞ったコンテキストに追加で約1000トークンです。合計トークン数を91%削減できたのです!
そして、それは1つの単純な最適化ループにすぎません。AIコードレビューの先駆者として、CodeRabbitは過去3年間、AIレビューにおけるコンテキスト規律、スマートなLLMルーティング、プロンプトキャッシングを支えるエンジニアリングと技術を磨き続けてきました。その蓄積された最適化は、顧客へ直接還元されます。私たちは、どのコンテキストが重要か、どのシグナルがノイズを増やすか、どのレビュー方式が本物のバグを見つけるかを理解しており、今も改善を続けています。
これが、CodeRabbitがコードレビューで最高のROIを提供する方法です。チームは高いパフォーマンス、予測可能なシートベースの料金、そして高スループットなエージェントループ向けの柔軟な従量課金アドオンを得られます。その結果、自信を持って高品質なコードをリリースできます。
AIコードレビューの目的は、より多くのトークンを消費することではありません。チームがより良いコードをより速くリリースし、本番環境での問題とレビューのボトルネックを減らすことです。
CodeRabbitが提供するのは、すべてのPRに対する高品質なレビューです。開発者は、もう1回レビューする価値が請求額に見合うかを気にせず、継続的なフィードバックを得られます。エンジニアリングリーダーは、レビュー品質がトークン支出によって配給されるのではなく、チームとともにスケールしているという確信を持てます。
Mergemaxxingはより良い指標です。すべてのPRがレビューされ、本物の問題が早期に見つかり、開発者は自由にイテレーションでき、自信を持ってコードをリリースできます。
トークン最大化の時代は終わりです。これからはマージ最大化です。
自信を持って高品質なコードをリリースする準備はできていますか。14日間の無料トライアルを始めるか、営業チームにお問い合わせいただき、予測可能なコストで最高水準のレビュー性能が自社リポジトリでどのように機能するかをご確認ください。


