
GetStarted in2 clicks.
GetStarted in2 clicks.

Opus 5 produced a cleaner actionable-comment stream, but caught fewer known issues and generated roughly four times the baseline's nitpicks. Here is where the model may fit — and where it does not.

Anthropic customers can now apply their existing Anthropic spend commitment toward CodeRabbit.
AI writes more code than humans can review. Logic errors are up 75%. Security issues nearly triple. Here's what replaces human review.
Opus 5 produced a cleaner actionable-comment stream, but caught fewer known issues and generated roughly four times the baseline's nitpicks. Here is where the model may fit — and where it does not.

Coding agents can expand change volume faster than teams can understand it. Review needs a shared path from intent to system behavior to code so people can keep shaping the system.
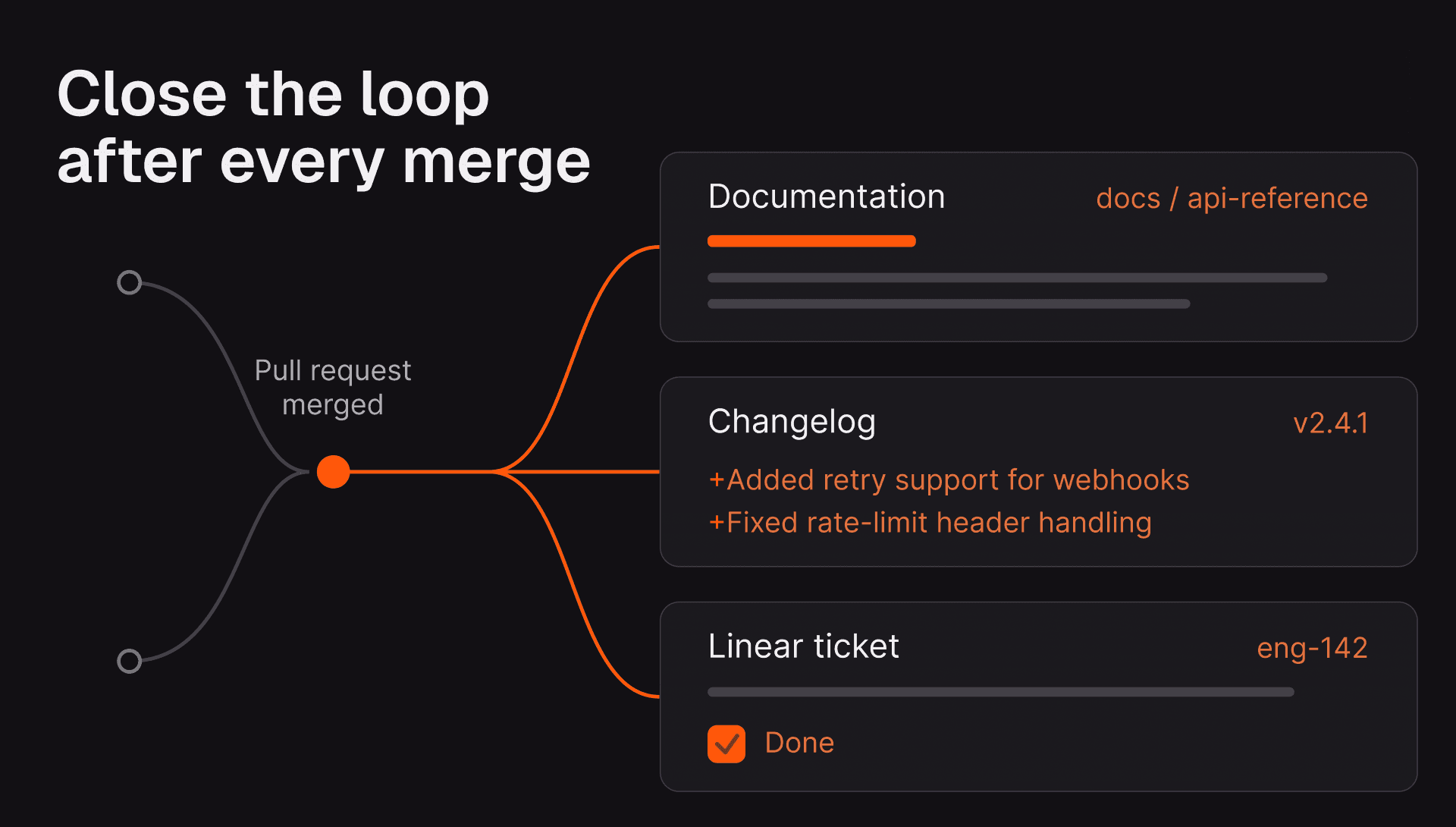
Post-Merge Actions use pull request context to handle changelogs, documentation, tickets, and other work that should happen after merge.

OpenAI’s GPT-5.6 family includes capability tiers: Sol as the flagship model, Terra as the lower-cost option, and Luna as the fastest, lowest-cost tier.
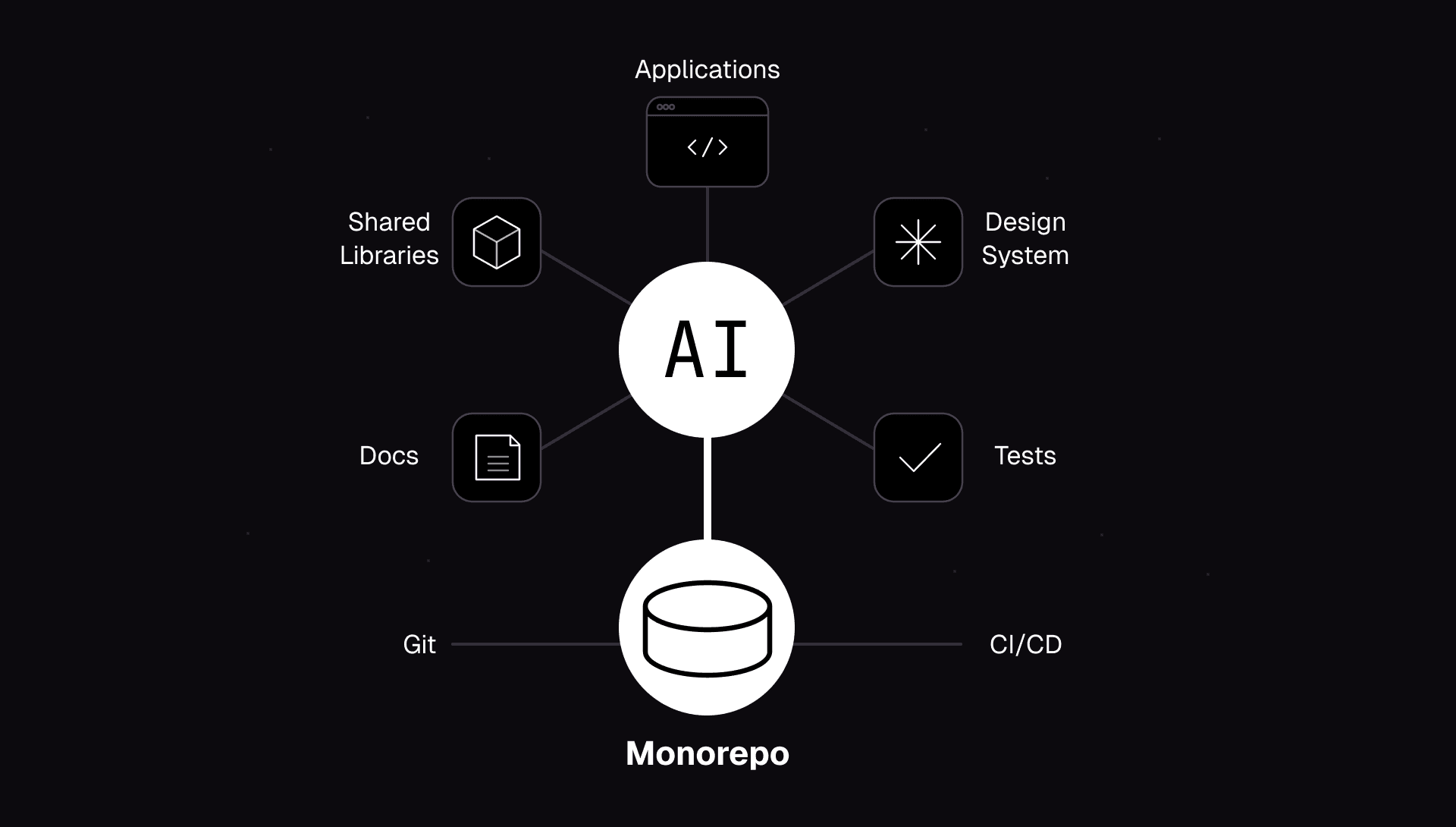
Monorepos keep shared code in sync but make every bad PR everyone's problem. Here's when to commit to one, when polyrepo wins, and how to review at scale.

A hands-on review of Claude Sonnet 5 after a week of real coding and code-review work: how it compares to Sonnet 4.6, what it costs, and who should upgrade.

Loop engineering allows you to step away completely by designing a system that operates autonomously, removing the human from the loop entirely.

How Ayush Sridhar CalHacks Hackathon project turned into an SWE internship with CodeRabbit

CodeRabbit can detect related repositories across your organization and use them as review context, so cross-repo impact is easier to catch before you merge.
Dig into insights about our products, use cases, and POVs