Aravind Putrevu
April 16, 2024
12 min read
April 16, 2024
12 min read
Share
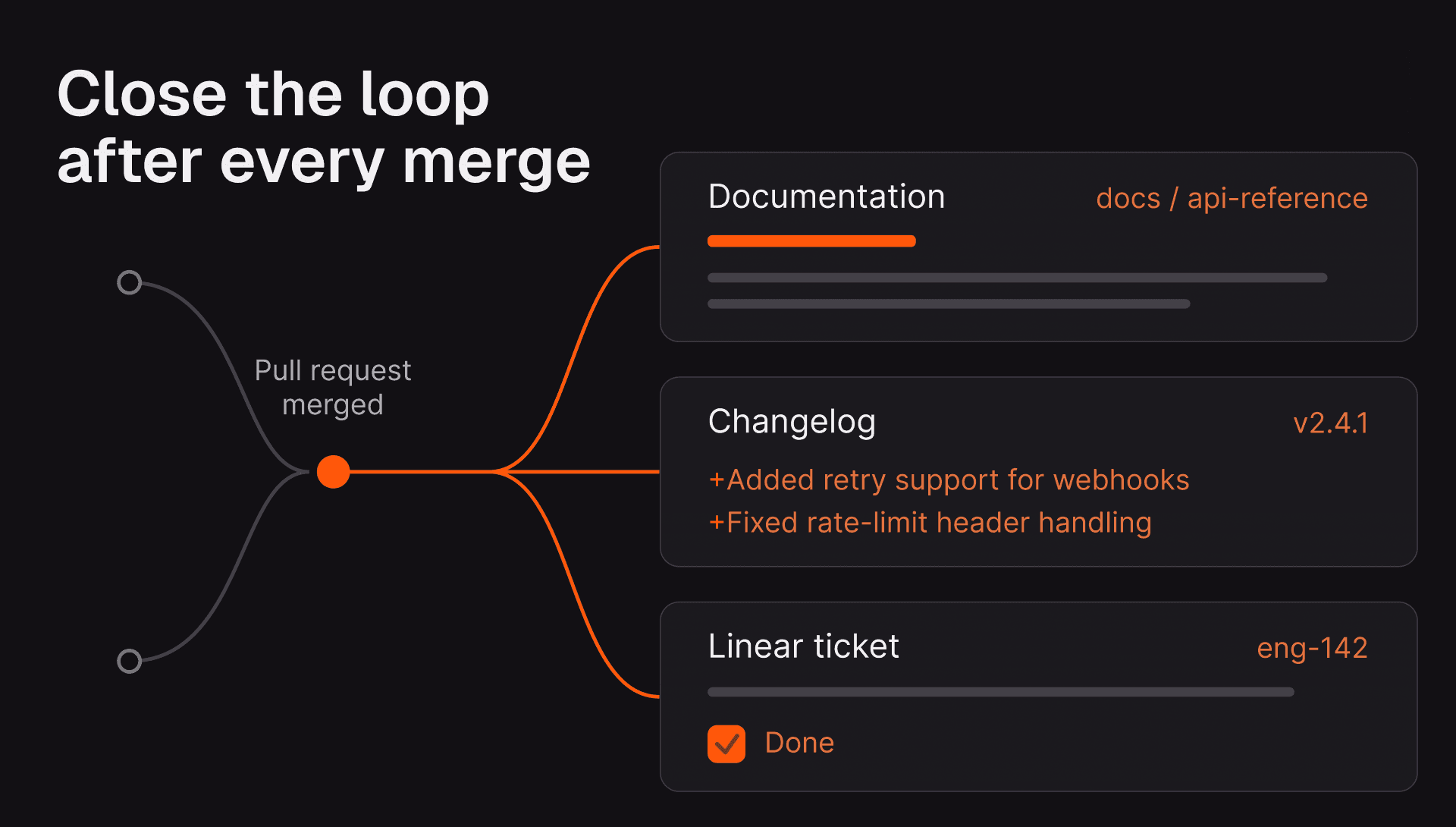
Cut code review time & bugs by 50%
Most installed AI app on GitHub and GitLab
Free 14-day trial
The fastest way to tank a team's ability to improve code quality is to exhaust the people responsible for maintaining it. Most teams know how to improve code quality in theory: write tests, enforce standards, review every pull request (PR).
The hard part is doing all of that without grinding senior engineers into dust. Adding more checklists, more review gates, and more meetings on top of an already-stretched team leads to resignations, not better software.
This piece covers the practices, metrics, and workflow patterns that actually improve code quality while keeping cognitive load manageable. You’ll learn how to automate the cheap stuff, shrink the review surface, and save human judgment for the decisions only humans can make.
Code quality in modern development is the degree to which an engineer unfamiliar with the codebase can change it correctly. That breaks down into a few concrete properties:
Maintainability: A non-trivial change doesn't break something the author didn't know existed.
Testability: There's a reliable way to know the change worked before it ships.
Security: Credential handling, input validation, and the failure modes that turn into post-mortems.
Code quality issues compound as technical debt. The work doesn't stop; it just costs more every time. The Stack Overflow Developer Survey 2024 confirmed that 63% of professional developers cite technical debt as their number-one frustration at work.
Quality debt slows your team even more than it slows the code, and the engineers who feel it first are the senior ones doing the most reviews.
Code review bottlenecks come more from cognitive load than scheduling. As teams grow, the volume of work that needs reviewing grows faster than the pool of senior engineers qualified to review it. Three structural patterns explain how that gap turns into a break:
PR size: Reviewers skim long diffs. Once a diff crosses the threshold of what one person can hold in their head, careful review turns into pattern-matching for the obvious stuff.
Reviewer load: Senior engineers carry the worst of the review burden, on top of architectural review, security review, and mentorship. JetBrains' Developer Ecosystem Survey 2025 confirms that coordination responsibilities increase with experience.
AI-generated volume: AI tools ship more PRs, and each PR carries more issues than human-only code. CodeRabbit's State of AI vs Human Code Generation Report analyzed 470 open-source PRs and found AI-co-authored PRs produce 10.83 issues per PR on average, compared to 6.45 for human-only PRs.
As a result, reviewer fatigue compounds, bugs slip through, and coding conventions fade because nobody has time to enforce them. Eventually, a senior engineer leaves, and the team realizes nobody else knew what the conventions were.
Two metrics do the load-bearing work: cycle time and defect escape rate. Pick a baseline, watch the trend, and the rest sorts itself out.
Cycle time is the time from when a PR opens to when it merges. It captures most of what goes wrong in review. If it's climbing week over week, something has shifted. PRs are getting bigger, reviewers are slower, or comments are stalling on low-priority issues instead of substance.
Cycle time hides two distinct problems, and the diagnosis matters. Long time-to-first-review means reviewer capacity is the constraint, so the fix sits on the reviewing side: automate the first pass, distribute load, cap incoming PR size.
Long time-in-review-cycles means feedback is unclear or comments stall on low-stakes issues, so the fix sits on the comment side: clearer review standards, written norms, prioritized blocking comments.
Track cycle time at the team level, not the individual level. Compare against your own historical baseline rather than an industry number.
Defect escape rate is the second metric worth watching. What percentage of bugs reach production instead of getting caught in review? Down means quality is improving. Up means something is broken upstream. If you don't tag bugs as "should have been caught" versus "genuinely subtle," start. The category split is where the actionable signal lives.
Numbers tell you what happened, but qualitative signals tell you what's about to happen. Watch for:
You know it's working when cycle time trends down or stays flat as PR volume grows, defect escape rate drops, first-review waits shrink, and senior engineers stop complaining about review burden.
None of these are numbers you can hit overnight. They move on quarter-scale, not week-scale, and the most reliable way to read them is against your own history.
Five practices move the needle on code quality the most, and none of them are new. The reason teams still ship buggy code is not that the practices are unknown; it's that the cost of executing them consistently has been higher than the cost of skipping them.
Small PRs are one of the biggest levers on review quality. Long diffs invite skimming, and skimming is how bugs reach production. A change small enough to hold in your head lets a reviewer give substantive feedback instead of pattern-matching across a sprawling diff.
Google's engineering practices documentation backs this up and gives reviewers explicit authority to reject changes solely for being too large. Smaller review units also reduce reviewer fatigue and move feedback through faster.
Trunk-based development is the practical enforcement layer for keeping PRs small. When everyone integrates into a shared trunk within a day or two, big speculative changes never get a chance to accumulate. Merge conflicts shrink, and reviewers see incremental work instead of multi-week dumps.
Feature flags handle the parts that aren't ready to ship, so the team can keep merging without exposing half-built features to users. The combination gives you frequent, low-risk merges and keeps the team in the habit of reviewing fresh code instead of archaeology.
Automated testing moves quality enforcement to the cheapest place to fix problems: before the code reaches a reviewer. A reliable suite of unit tests for logic, integration tests for boundary behavior, and a small set of end-to-end tests for critical paths catches the failures that would otherwise eat review time.
Tests run in continuous integration (CI) on every PR, fail loudly, and block the merge until resolved. The point isn't 100% coverage; it's coverage on the paths that actually fail. Done right, human reviewers stop verifying basic correctness and start focusing on design, edge cases, and the failure modes the tests don't cover.
Static analysis and linting belong in the pipeline as automated guardrails, not human checklists. Run them pre-commit or in CI so structural issues, type mismatches, common security patterns, and style violations get flagged before any reviewer sees the diff. The mechanical layer should catch the mechanical problems.
A reviewer who has to comment on missing null checks or unused imports is spending cognitive load that should go toward design and logic. Combine the tools rather than picking one:
A linter for style
A type checker for correctness
A static application security testing (SAST) scanner
Each catches a different class of issue, and the overlap is small.
Shared coding conventions remove the most predictable arguments from code review. Document the patterns your team agrees on: naming, file organization, error handling, testing structure, and what "done" actually means for a PR.
Make as much of it machine-enforceable as you can. A formatter handles whitespace, while a PR template enforces the definition of done.
The work of standardization happens once, and it pays out every time a reviewer doesn't have to explain a convention from scratch. When conventions live only in a senior engineer's head, drift is inevitable. But when they live in code and tooling, drift is hard.

Together, these practices compound. For example, freee, a Tokyo-based business management SaaS company, saved the equivalent of 32.8 weeks of reviewer time over six months after pairing these practices with AI code review. The deployment expanded from a 30-seat pilot to 570 seats across 285 repositories.
When the team agrees on what every reviewer should check, standards drift disappears. A useful checklist covers six things:
Functionality: Does the code do what it claims? Are edge cases handled? Are failure paths tested?
Logic and correctness: Conditional logic, error handling, null safety, and concurrency. These are the categories CodeRabbit's State of AI vs Human report flags most heavily in AI-generated code.
Readability: Variable names, structure, and comments where complexity warrants them. Skip the formatting wars. Let the formatter handle those.
Security: Credential handling, input validation, and common injection patterns. Catch these in review, not in a post-mortem.
Tests: Does the test cover the behavior, not just the implementation? Do the tests fail when the code is wrong?
Documentation: Public APIs, non-obvious decisions, and breaking changes need a note.
That's the human reviewer's job. Style, formatting, and obvious linting violations should be caught earlier in the pipeline.
The cost of async review is round count. Each back-and-forth eats a day, so the teams that ship across time zones optimize to land the review in one or two passes, not to be faster, but to require fewer rounds.
Four practices keep the round count low:
Pre-annotate non-obvious code in the PR description: Walk the reviewer through the changes before they see the diff. The first round of "what is this doing?" should be answered before they ask.
Make every comment self-contained: Include the actual question and the actual ask. "Thoughts?" forces a follow-up. "Can we extract this into a helper to avoid duplicating the validation logic?" gets answered in one round.
Mark comments as blocking vs. non-blocking: Authors need to know which comments must be addressed before merge and which are suggestions. Without that signal, every round becomes a clarification round.
Set a primary reviewer: Multiple reviewers in different time zones, each waiting on the others, means PRs rot. Name one primary; mark the rest optional.
The teams that handle this well treat async review as a design problem, not a scheduling problem.

Taskrabbit fixed exactly this before adopting AI coding agents. With engineering split between San Francisco and Poland, PRs opened after 2 pm PST waited a full day for the first review.
After deploying CodeRabbit, the average PR cycle time dropped from 10 days to 7, a 25% reduction. Senior Engineering Manager Kiran Kanagasekar described the logic plainly: "Writing code faster was never the issue; the bottleneck was always code review."
AI code review works as a first-pass filter that preserves human reviewer capacity for the decisions that actually need it. The categories AI handles well are the ones that wear humans out: catching null checks the author forgot, flagging unused imports, surfacing common security patterns, and spotting style inconsistencies. The categories where humans still win are the ones that require domain context: design, architecture, and the question of whether this change makes sense for what the team is actually trying to build.
The split is clean:
That split is what makes the workflow sustainable. When a human reviewer opens a PR and the mechanical issues have already been flagged, they get to spend their attention on the questions worth asking. CodeRabbit, the AI code review platform, runs this first pass everywhere developers work: pull requests, IDEs (VS Code, Cursor, Windsurf), CLI, and mobile code review through Slack.
Every PR gets a walkthrough summary and a run of 40+ bundled linters and SAST tools inline before a human sees it.
The standards-enforcement angle matters just as much. Teams encode their conventions once into CodeRabbit Learnings, Code Guidelines, or path-based rules, and CodeRabbit applies them during pull request reviews. The rules live in the review process instead of a Notion page nobody reads.
Sustainable code quality comes from treating reviewer attention as a finite resource and building systems that protect it. The work happens in layers: pre-commit checks before the PR opens, AI review handling the first pass, humans focused on design and architecture, CI/CD validating the merge.
Each layer catches what the previous one missed, and the combination keeps the team shipping quality code without grinding through the people who write it. Ready to make code review sustainable for your team? Get a 14-day free trial of CodeRabbit today.