
CodeRabbit is now in the Claude Marketplace!Learn more


Aravind Putrevu
Ankur Tyagi
December 04, 2024
8 min read
December 04, 2024
8 min read
Share
Cut code review time & bugs by 50%
Most installed AI app on GitHub and GitLab
Free 14-day trial
This is the second in a series of posts we intend to write about how to do code reviews as simply and quickly as possible. In the last article, we discussed how CodeRabbit helps boost productivity and spot issues in large TypeScript projects, and it’s worth revisiting.
This time, we’re going a step further—We'll show you how CodeRabbit improves Python code quality beyond what typical linters can do. By the end, you’ll see how it makes Python code reviews smoother and more efficient.
Before we start, let’s see why “code reviews are so time-consuming and challenging for reviewers and developers.“
Code reviews can sometimes be a pain. They're more than just another routine task for developers. Reviewers often go back and forth, nitpicking over preferences instead of real issues. Conflicting opinions? That’s a whole other headache—especially when multiple reviewers disagree. And then there’s the back-and-forth because the dev didn’t get the comments or didn’t hit the expected quality bar. Add unclear expectations, and the whole process can feel like it’s dragging on forever.
These fundamental issues aren’t explicitly tied to Python or any other programming language but are common in any code review process.
Let’s see what typical code review challenges developers see when working explicitly with the Python codebase.
As we saw with the introduction, developers have different views on what the goal of a code review is. Some developers think that it’s about finding technical issues, others view it as a tool to verify the functional requirements of the code.
Let’s see what specific challenges we face in a Python code review.
# Code below demonstrates a PEP 8 violation: Improper spacing around operators and missing spaces after commas
def calculateUserAge(user_birthdate, current_date):
age = current_date.year - user_birthdate.year # Inconsistent spacing around the operator
return age
Difficulty in tracking type-related bugs due to Python's dynamic typing
Confusion about when to use type annotations
Example:
# Problematic: Lack of clarity on the type of 'data' and its expected methods
# The code assumes 'data' has a 'transform' method, but the type of 'data' is not specified.
def process_data(data):
return data.transform() # What type is 'data'? What methods should it have?
Most of the problems in software engineering do not come from unoptimized code. Most of the problems in software engineering come from the mess we have in our code.
Unnecessary complexity in implementations
Convoluted logic flows
Overuse of conditional statements
Failure to use Python's built-in features
Example
# Problematic: Unnecessary complexity and deep nesting
# The code uses multiple nested 'if' statements, which make the logic harder to follow.
def get_user_status(user):
status = None
if user.is_active:
if user.last_login:
if (datetime.now() - user.last_login).days < 30:
status = "active"
else:
status = "inactive"
else:
status = "never_logged_in"
else:
status = "disabled"
return status
Circular imports and unclear dependency hierarchies
Mixed absolute/relative imports
Example:
# Problematic: Circular import between file1.py and file2.py
# file1.py imports ClassB from file2.py, and file2.py imports ClassA from file1.py.
# This creates a circular dependency that can lead to ImportError or unexpected behavior.
# file1.py
from file2 import ClassB # Circular import
class ClassA:
def method(self):
return ClassB()
# file2.py
from file1 import ClassA # Circular import
class ClassB:
def method(self):
return ClassA()
Inconsistent project structure and mixing business logic with infra code
Unclear separation of concerns
Example:
# Problematic: Lack of modularization and responsibility segregation
# The 'create_user' method is performing multiple tasks (validation, database connection, sending emails, and logging).
# This violates the Single Responsibility Principle (SRP) and can make the code harder to maintain or extend.
class UserService:
def create_user(self, data):
# Validates data
# Connects to database
# Sends welcome email
# Logs to monitoring system
pass
Test coverage — is controversial and it depends but, we don’t think 100% coverage as a target is a good idea, but we think you should be measuring and reporting coverage during your test runs.
Instead of treating it as a target, treat it as a warning and if coverage suddenly drops, then it’s likely a sign something else has gone wrong in either the main codebase or the test suite and writing tests is cheaper than not writing them.
Insufficient test coverage and unclear test intentions
Long and bad test suites
Example:
# Problematic: Bad testing practice - insufficient validation and lack of edge case testing
# The test only checks if the user is not None, which is not a comprehensive validation of the user creation process.
# The test should verify whether the user was created with correct attributes and handle edge cases such as invalid input,
# missing data, or errors during creation. This test lacks assertions for data correctness and doesn't test failure cases.
def test_user_creation():
user = create_user("john", "doe", 25)
assert user is not None # This assertion is too basic and doesn't validate correctness
Inefficient data structures usage and memory leaks
Unnecessary computations
Example
# Problematic: O(n) lookup performance issue
# The current implementation performs a linear search (O(n)) through the 'users' list, which can be slow for large datasets.
# As the size of 'users' grows, the lookup time increases linearly, causing performance degradation.
def find_user(users: list, user_id: int) -> Optional[User]:
for user in users:
if user.id == user_id:
return user
return None
Inconsistent error handling patterns
Too broad exception catching
Missing error logs
Example:
# Problematic: Poor error handling - catching all exceptions and logging them without context
# The code catches all exceptions using a generic 'Exception' class, which can hide specific errors and make debugging difficult.
# Additionally, it only logs the error message without providing useful context about where the error occurred or the state of the application.
try:
do_something()
except Exception as e:
log.error(e) # Too generic and lacks context, making debugging harder
No doubt Ruff is very fast.
Using a linter like Ruff can significantly improve code quality, but it also comes with particular challenges, noise, and the need for manual intervention on every PR/Change.
Docstring enforcement - Ruff may flag missing or inconsistent docstrings, which can be annoying in smaller projects.
Code complexity - Ruff includes rules like the mccabe complexity check, which might flag complex code but still maintainable in context. Code refactoring based on these suggestions can sometimes be unnecessary, especially in smaller functions.
Isort integration - Ruff includes import order checks, which can get noisy, particularly if you have frequent import changes or a dynamically loaded module structure.
Ruff doesn't support custom rules or plugins, which is its most significant current limitation.
Let us run CodeRabbit on a popular Python repo for developing Autonomous AI Agents!
CrewAI is a Python framework for orchestrating role-playing autonomous AI agents. Let’s do a live testing of CodeRabbit on the CrewAI repo:
Go to the CrewAI GitHub repository.
Click the “Fork” button at the top right corner of the page to create a copy of the repo in your own GitHub account.
Clone the repo to your local machine:
Open your terminal or Git Bash.
Run the following command to clone your fork
git clone https://github.com/<your-username>/crewAI.git
Select any existing branch:
cd crewAI
git checkout <branch-name>
Make a small change:
Open the repo in your preferred code editor (e.g., VSCode).
Make a small change to any file. For example, add a comment or modify an existing one.
Commit the changes:
git add .
git commit -m "Made a small change for testing CodeRabbit"
Push your branch back to your forked repo:
git push origin <branch-name>
Raise a Pull Request (PR):
Go to your GitHub fork and click the “Compare & pull request” button.
Review your changes and click “Create pull request.”
Create the pull request and see CodeRabbit in action
Ensure you're logged in to CodeRabbit using your GitHub account
Add your forked repository to CodeRabbit dashboard at https://app.coderabbit.ai/settings/repositories
Pro Tip: CodeRabbit only reviews repositories that are explicitly added to your dashboard. If you don't see the AI reviewer on your PR, this is likely the reason.
For more detailed setup instructions, visit the CodeRabbit documentation.
Let’s take a look at some of the results which we get after the review done by CodeRabbit of this pull request.
Here are the key findings from CodeRabbit's code review:
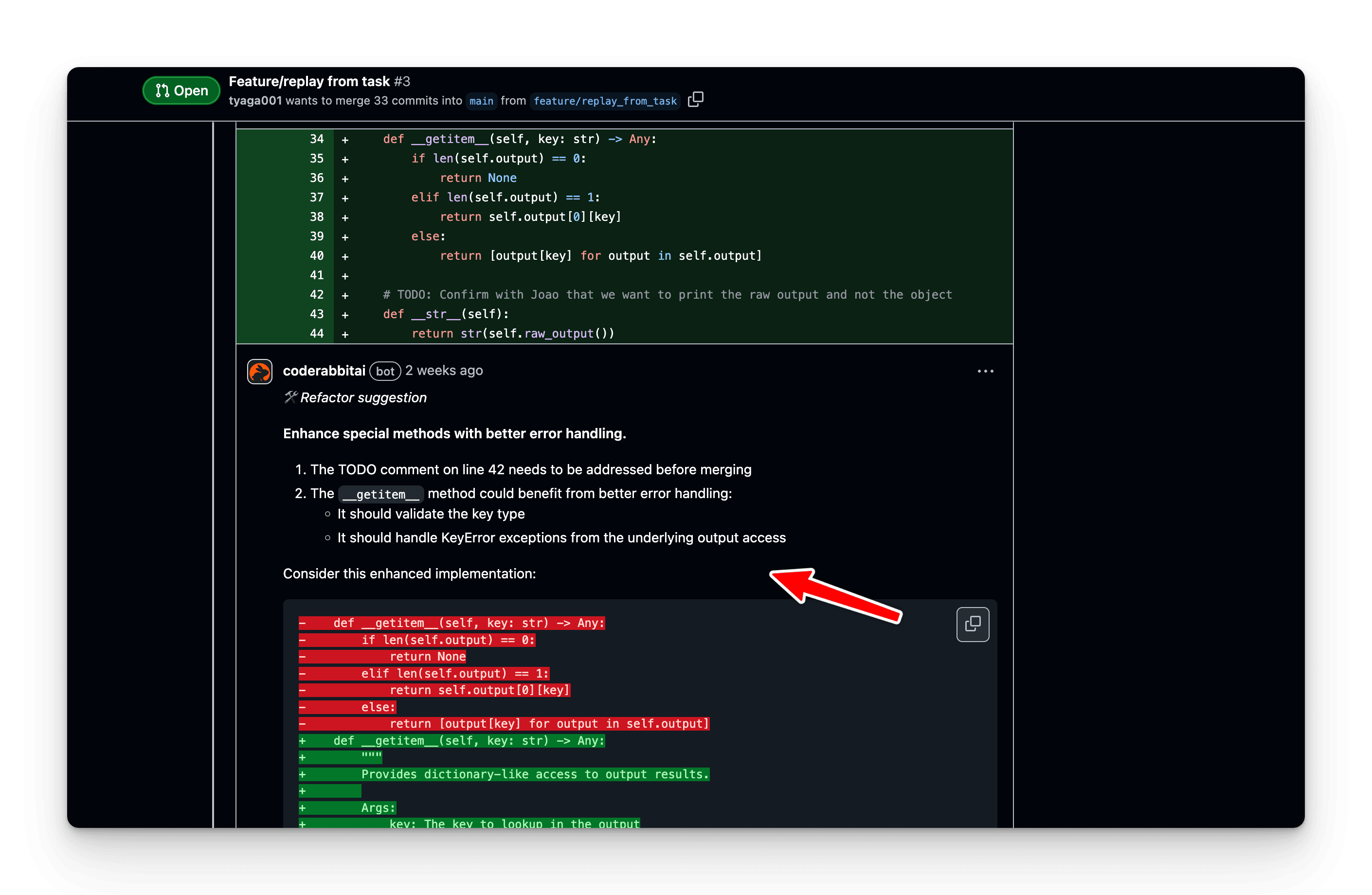
Special Methods Enhancement:
__getitem__ method needs better error handling
TODO comment needs to be addressed before merging
Suggestion to validate key types and handle KeyError exceptions
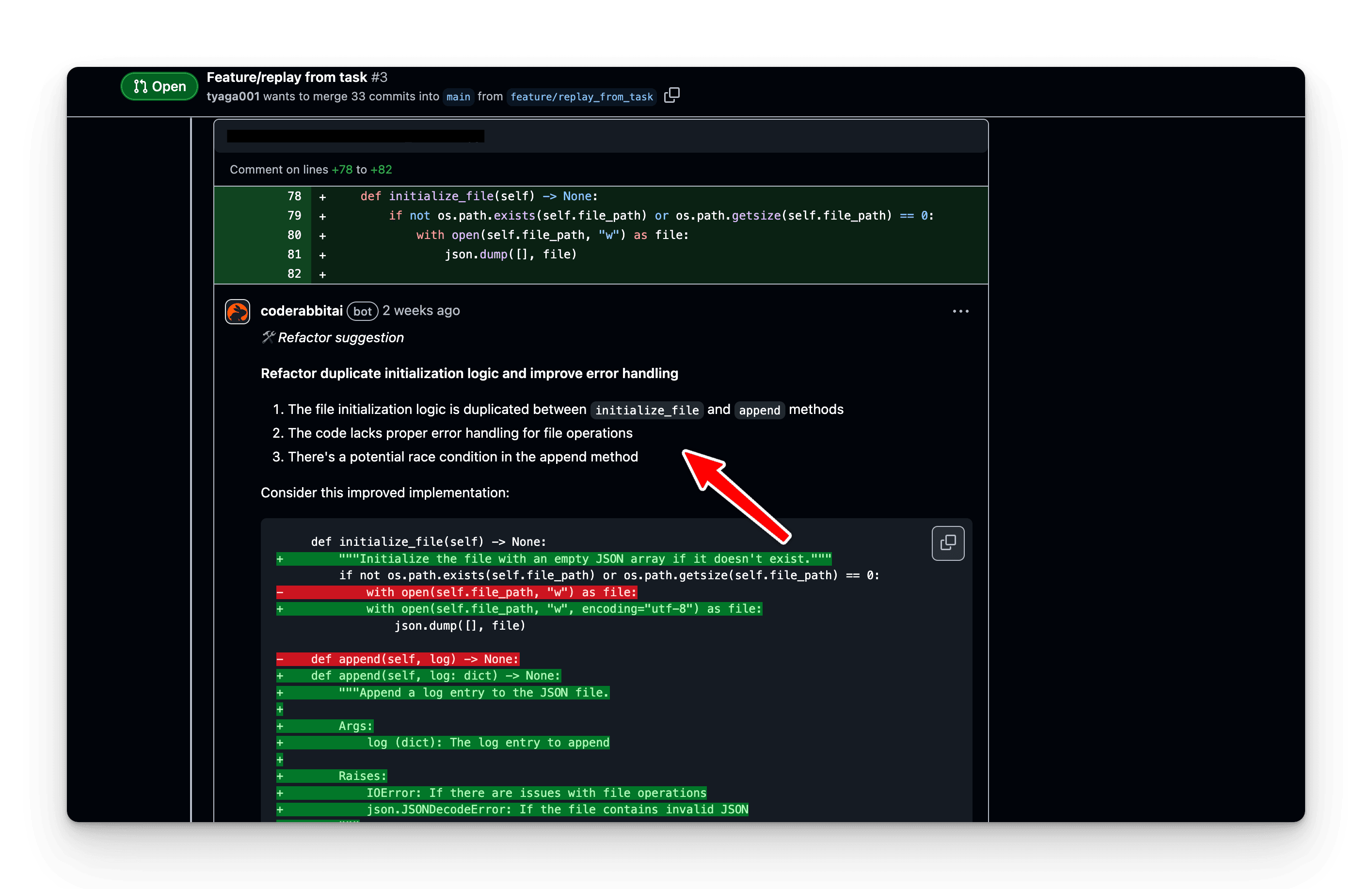
File Operations Issues:
Duplicate initialization logic between methods
Potential race condition identified in append method
Need for proper error handling in file operations
Missing UTF-8 encoding specification
Test Coverage Gaps:
Missing test coverage for TaskOutputJsonHandler
While PickleHandler is tested, JSON handler implementation needs coverage
Task Creation Redundancy:
Potential duplicate task creation in kickoff_for_each_async
Risk of tasks being scheduled multiple times
For the complete review and discussion, check out the PR.
The best part? CodeRabbit suggests the 1-click fixes right in the code review comment.
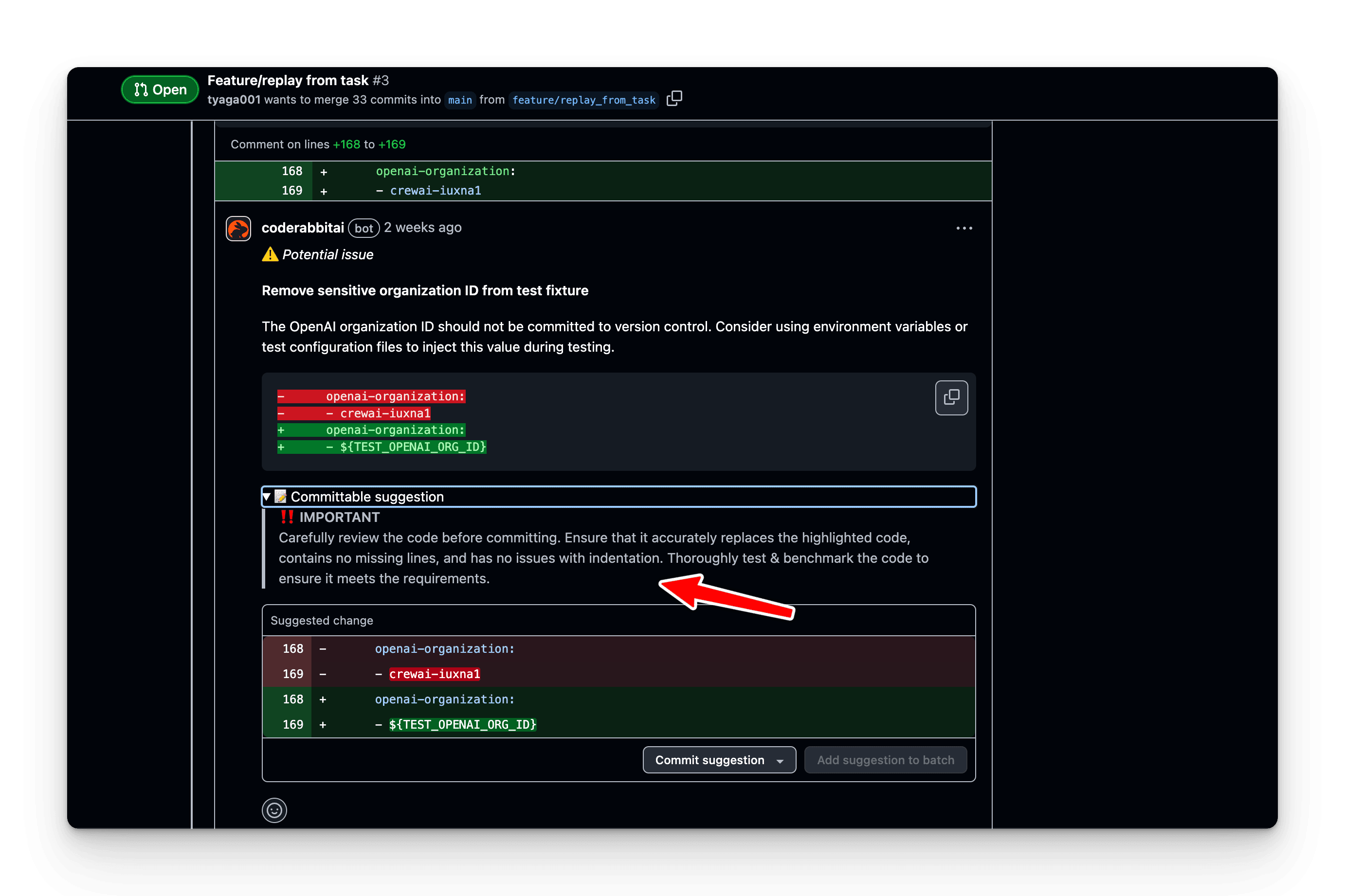
No more back-and-forth between developer and reviewer in PR comments.
We understand that you may have experimented with various linters or other AI tools for code review, but CodeRabbit seamlessly integrates into the GitHub workflow without any additional steps. Simply create a pull request, wait approximately five minutes, and you'll receive a comprehensive analysis of code issues before any manual review takes place.
If you're a developer or a founder who conducts code reviews frequently, consider the time spent on minor issues like formatting adjustments, naming conventions, or optimizing loops. With CodeRabbit, you can shift your focus to more critical aspects, such as evaluating whether the code effectively addresses user needs or assessing its stability for production deployment.
We've explored the common challenges in Python code reviews, from PEP8 compliance to complex architectural issues, and showed how CodeRabbit goes beyond traditional linters to provide intelligent, context-aware solutions. By automating the tedious aspects of code review, CodeRabbit helps teams focus on what truly matters - building great software.
Sign up to CodeRabbit for a free trial and experience automatic reviews that enhance your application's quality while helping your team work faster and better. You can also join the Discord channel to connect with a community of developers, share insights, and discuss the projects you're working on.
PS: It is free for Open-source projects.



