


NVIDIA Nemotron 3 Ultra does not feel like another model built primarily for a chat window. The first question is not whether it can win a leaderboard, but whether it can fit into the way developers actually use models now: inside terminals, review pipelines, coding agents, test generators, and workflows where the model has to keep moving through messy context.
NVIDIA is releasing a large open model with roughly 550 billion total parameters and about 55 billion active per token, but the real pitch is speed plus control. If a model is fast enough, a developer can stay in the loop. A system can retry it. A coding harness can keep it working until the task is actually finished.
Ultra is not the model I would frame as "the new best coding assistant." It points toward a world where open models become fast, controllable workers inside developer systems, not just chat interfaces waiting for the next prompt.
For workflows where the model is one part of a larger loop, Nemotron 3 Ultra becomes especially relevant: code review, test generation, repository research, agentic coding, and internal automation where teams care about speed, control, and where the model runs.
What we know about Nemotron 3 Ultra
Nemotron 3 Ultra is the largest model in NVIDIA's Nemotron 3 family. The family includes Nano, Super, and Ultra, all designed around agentic AI applications. Ultra is the big reasoning engine in that lineup: roughly 550 billion total parameters, with about 55 billion active per token through a sparse mixture-of-experts design.
The cleanest comparison is with Nemotron 3 Super, the previous large model in the family.
| Characteristic | Nemotron 3 Super | Nemotron 3 Ultra |
| Role in the family | High-throughput reasoning model for agentic workflows | Largest Nemotron 3 reasoning model for more complex coding, research, and enterprise workflows |
| Total parameters | 120B | 550B |
| Active parameters | 12B active per token | 55B active per token |
| Architecture | Hybrid Mamba-Transformer MoE | Hybrid Mamba-Transformer MoE |
| Expert design | Latent MoE | Latent MoE |
| Context length | Up to 1M tokens | Up to 1M tokens |
| Efficiency features | Multi-token prediction and NVFP4 training/deployment path | Multi-token prediction and NVFP4-oriented deployment path |
| Best fit | High-volume agentic workflows, coding, planning, and tool use | More demanding developer workflows where speed, scale, and stronger reasoning need to sit in the same loop |
In simpler terms: this is not just a bigger dense Transformer. Ultra is built to activate only part of the network per token, keep long context practical, and produce tokens quickly enough that developers can use it interactively instead of treating it like a slow background batch job.

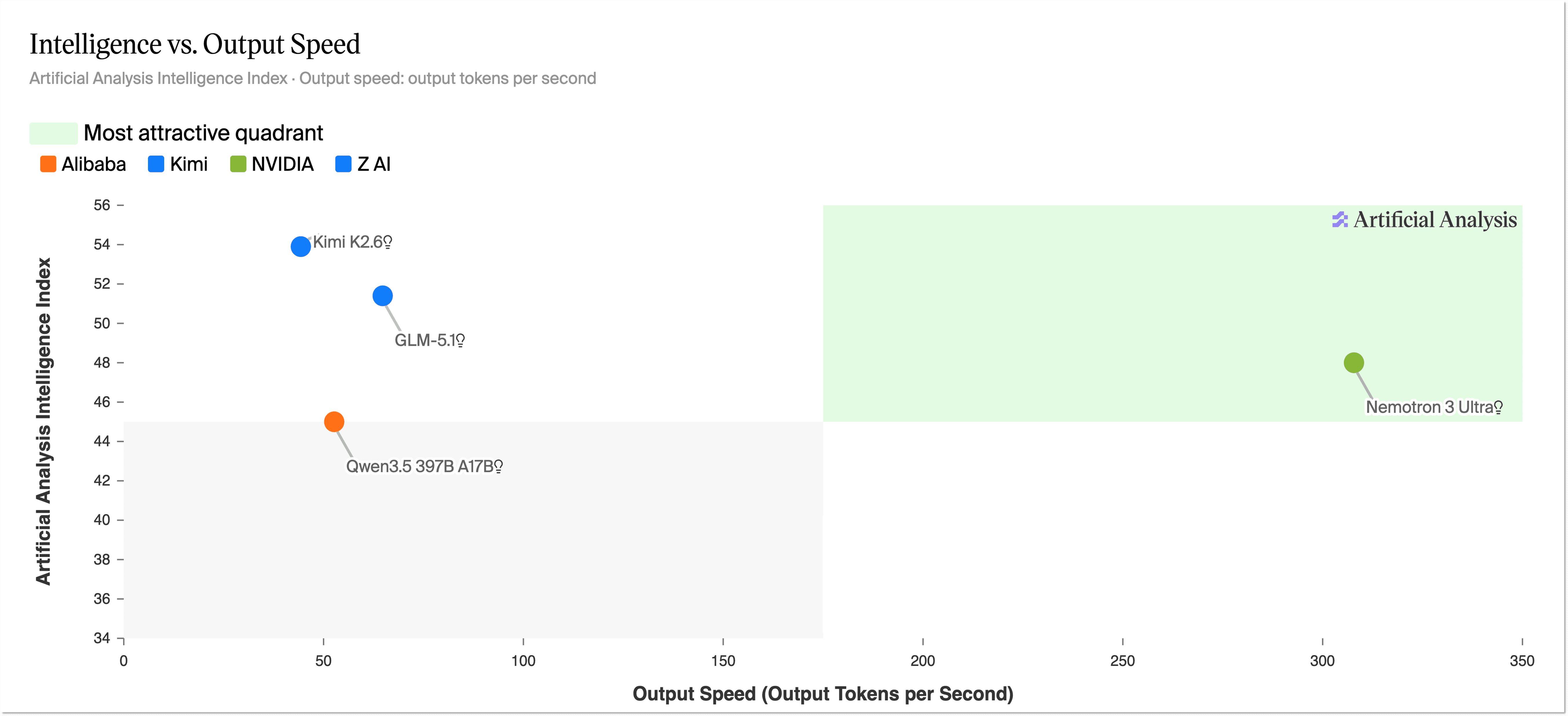
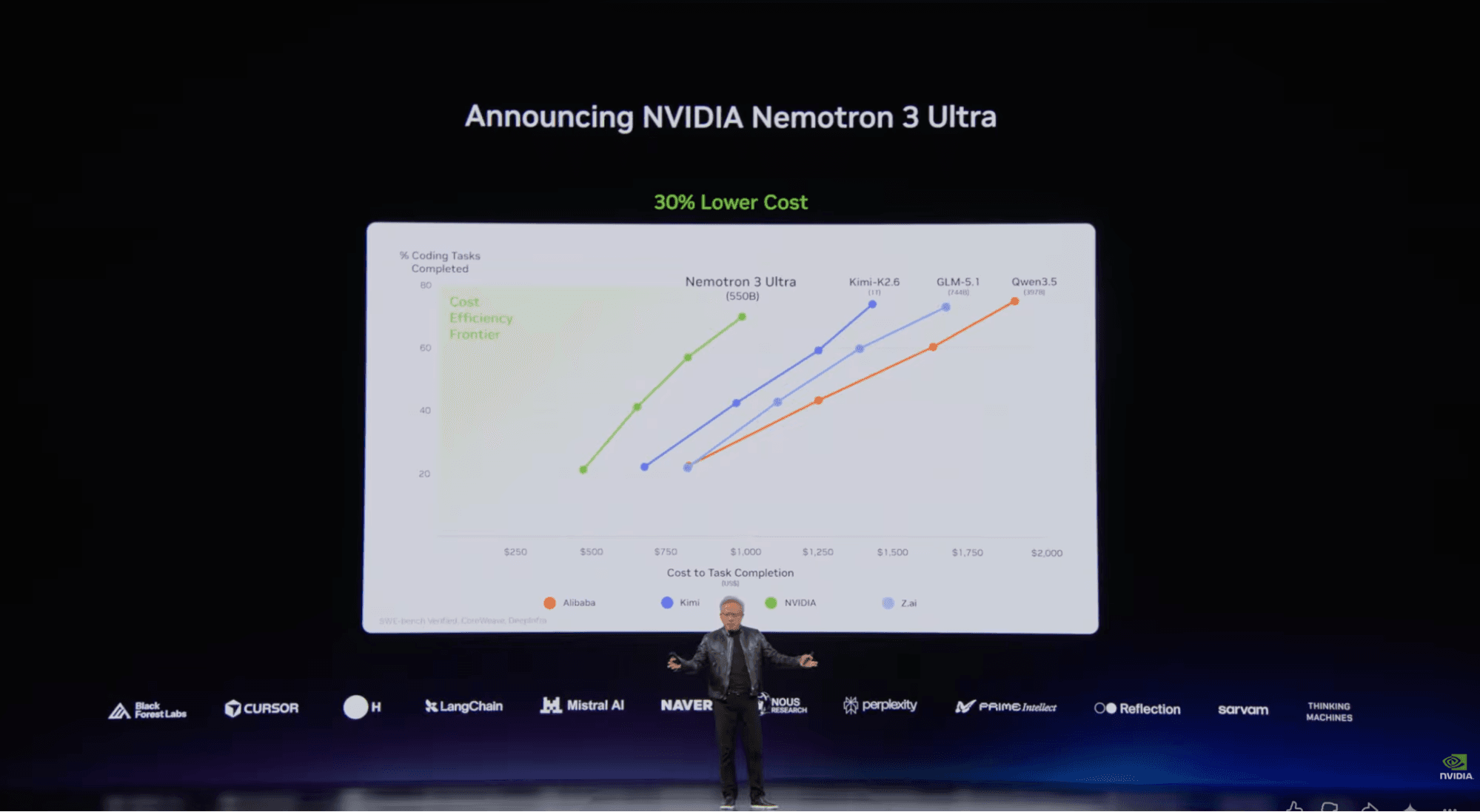
The launch numbers put Ultra in a strong spot. Artificial Analysis reported Nemotron 3 Ultra at 48 on its Intelligence Index, making it the leading US open-weight model in that snapshot, ahead of Gemma 4 31B, Nemotron 3 Super, and gpt-oss-120b. Kimi K2.6 still sits higher at 54, so the claim is not that Ultra owns the entire open frontier. The claim is that it is unusually fast for the intelligence level it reaches.
Artificial Analysis also reported more than 300 output tokens per second on a pre-release DeepInfra endpoint. For developers, that speed is the useful part. In coding, latency changes behavior. If a model is slow, you fire and forget. If it is fast, you stay in the loop, ask follow-ups, run multiple attempts, and let an agentic harness keep pushing.
What is different this time
Nemotron 3 Super already showed that NVIDIA could build a capable open model for agentic workflows. Ultra pushes further in two ways.
First, it is much bigger. Super is around 120B total parameters with roughly 12B active. Ultra moves to roughly 550B total and 55B active. That extra scale shows up in the way NVIDIA and early testers talk about it: not as a small efficient helper model, but as a model that can start taking work from proprietary frontier systems in selected workflows.
Second, Ultra appears to have been trained and evaluated with developer harnesses more directly in mind. NVIDIA mentions that Super turned out to be good in agentic harnesses, while Ultra was built with those harnesses in mind. For coding tools, that changes the requirements. A model that works well in OpenCode, OpenHands, Kilo Code, Continue, or an internal code review loop has to do more than answer questions. It has to follow tool protocols, manage long context, make progress under repeated prompts, and recover when it gets stuck.
Ultra's behavior fits that target. The model is quick, direct, not especially verbose, and unlikely to ask for lots of clarification. That can be a strength in a harness, but a weakness if the task depends on unstated requirements. It benefits from explicit instruction. The best mental model is closer to Codex-style prompting than Claude-style prompting. Spell out the task. Give acceptance criteria. State the expected output format.
CodeRabbit Benchmark Performance
CodeRabbit's internal benchmark gives a more grounded view than launch charts alone. The benchmark compares a baseline set of review models against a Nemotron 3 Ultra configuration across 105 evaluation problems, ranging from easier issues to harder review tasks. The evaluation uses post-pipeline final comments after verification, deduplication, and assertive filtering. The judge was gpt-5.1 with medium reasoning, low verbosity, single mode, and three votes.
The top-line result is close:
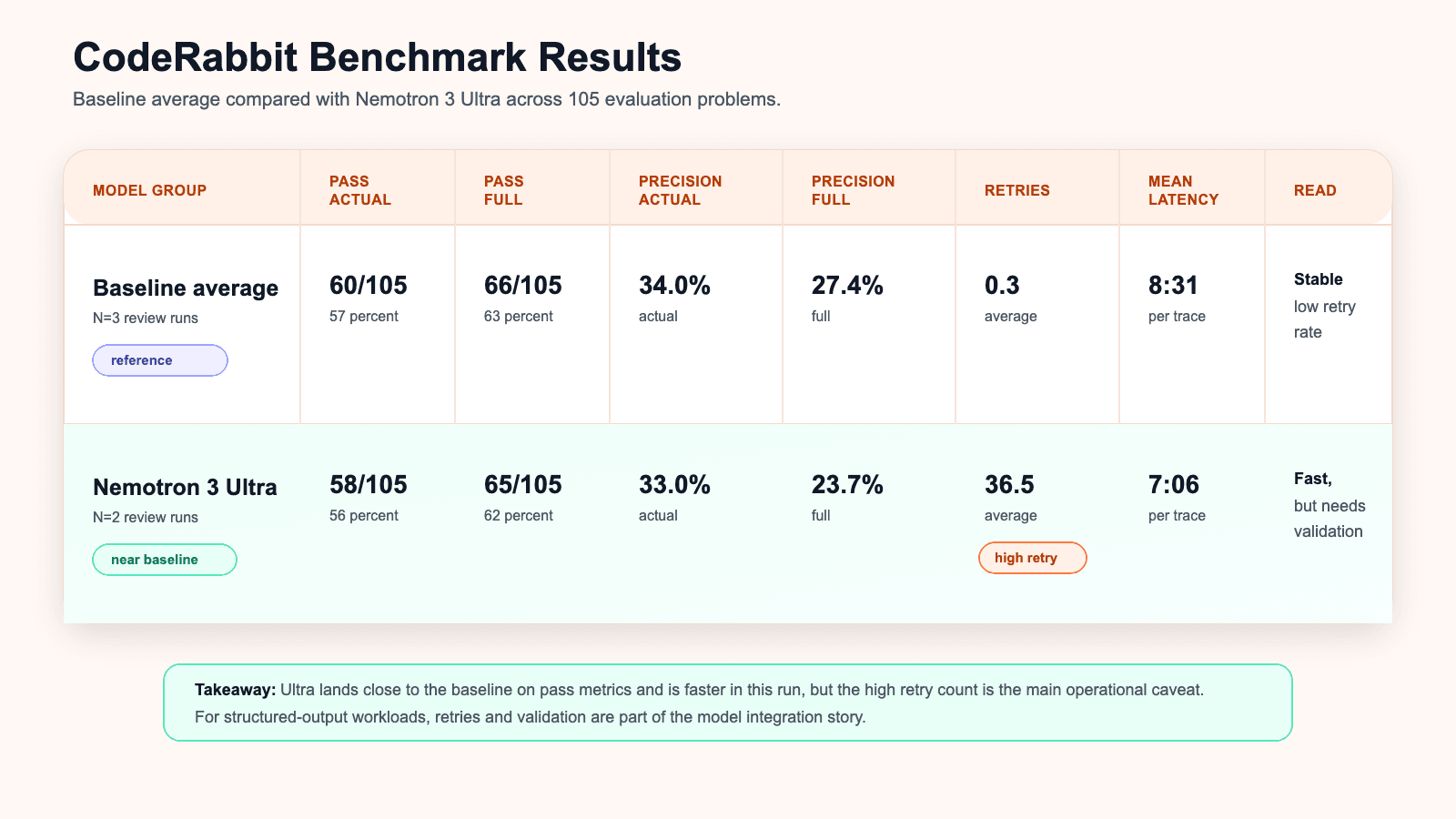
- Baseline average, N=3: 60/105 pass actual, or 57 percent
- Nemotron 3 Ultra average, N=2: 58/105 pass actual, or 56 percent
- Baseline pass full: 66/105, or 63 percent
- Nemotron 3 Ultra pass full: 65/105, or 62 percent
- Baseline precision actual: 34.0 percent
- Nemotron 3 Ultra precision actual: 33.0 percent
The positive read: on this review workload, Ultra was roughly in the same band as the baseline on pass metrics. It found real issues, survived the review pipeline, and produced useful CodeRabbit-style comments.
The caveat is reliability. The model had a high retry rate. The benchmark summary shows an average of 36.5 retries for the Ultra runs, compared with 0.3 for the baseline. The retry distribution notes that about 66 percent were scratchpad-only. In practice, the model sometimes voluntarily stops before producing the required output marker or final structured output. Retrying without changing the prompt often works, which suggests the capability is there, but the first-attempt completion behavior is not stable enough to ignore.
The practical finding from the CodeRabbit data is clear: Nemotron 3 Ultra can do the work, but it should be wrapped in validation and retry logic for structured-output tasks.
There is also an interesting latency signal. In the benchmark, the Ultra run shows a mean latency of 7:06 per full review trace, compared with 8:31 for the baseline. That is not an enormous difference in this specific report, but the Ultra runs were carrying a large retry burden and still remained competitive on time. NVIDIA's framing around Ultra repeatedly returns to the same idea: if the model is fast enough, several attempts can still beat one slower, more careful attempt.
The cost story is less clean in the benchmark. The reported total cost for the Ultra run is higher than the baseline in this specific table. That should not be over-generalized, because internal fallback rates, hosted endpoint pricing, and retry behavior can dominate a local experiment. The public NVIDIA and Artificial Analysis story is about cost-to-completion and throughput. The CodeRabbit results say something narrower: on this benchmark, quality was close, speed was competitive, and the reliability control loop needs work.
Where Ultra looks strong for developers
The strongest use case for Nemotron 3 Ultra is not "replace every coding model." It is "run a lot of useful developer work quickly, with explicit instructions and external checks."
It looks promising for:
- Code review pipelines where comments can be verified, filtered, deduplicated, and retried
- Integration test generation, especially when the model needs to read broad context
- Repository research tasks that require scanning many files or documents
- Agentic workflows where a harness can keep the model moving until the task is complete
- Everyday coding tasks that benefit from fast iteration more than perfect one-shot reasoning
NVIDIA also shared a useful example: Ultra was used in OpenCode to read several papers and reason across them. That is not a PhD-level coding challenge, but it is exactly the kind of everyday developer task where speed changes the workflow. You can stay in the terminal, watch the model move, and keep steering.
For CodeRabbit-style work, the model also seems especially interesting on easier and medium-difficulty review tasks. These are still valuable reviews: the system needs to catch practical issues, explain them clearly, and produce a lot of review output without waiting on a more expensive frontier model every time.
What developers should watch out for
Ultra needs structure. If you are using it for coding or developer automation, do not treat it as a free-form chat model and hope it infers the workflow. Give it a harness. Give it a checklist. Give it stop conditions. Give it output validation.
Practical guidance:
- Use explicit prompts with concrete acceptance criteria.
- For structured output, validate the required markers or schema before accepting the response.
- Add retry logic for premature stops.
- Use goal loops or external completion checks so the model keeps working until the task is actually done.
- Ask for tests explicitly. In early hands-on use, the model did not always generate its own tests.
- Be specific about design requirements. It can produce better visual artifacts than expected, but design is not its core strength.
- Prefer it for high-throughput workflows where several attempts are acceptable.
- Be cautious for workflows where a single malformed output can break production automation.
This model also changes how teams should think about benchmarking. A pure one-shot benchmark may underrate Ultra if the real product loop allows retries. A benchmark that ignores retries may overrate it if the product needs strict first-attempt formatting. The right metric is probably closer to time-to-usable-completion, with quality, retries, latency, and cost all measured together.
Verdict
Nemotron 3 Ultra is one of the most interesting open model releases for developers because it is not only chasing intelligence. It is chasing usable throughput.
The model is big, open, and fast. Public benchmarks put it near the top of US open-weight intelligence while keeping it far ahead of many peers on output speed. CodeRabbit's benchmark adds a more sober picture: Ultra can perform close to a strong review baseline, but it currently needs retries and external validation for structured-output reliability.
The verdict is nuanced. If you want a model that will nail every strict format on the first try, Ultra is not yet the safest default. If you are building an agentic developer system where the harness can validate, retry, and keep pressure on the model until the work is complete, Ultra becomes much more compelling.
For coding teams, the bigger story is not whether Nemotron 3 Ultra replaces a favorite chat model. It is whether open, high-throughput coding agents are starting to feel practical.
Try it on CodeRabbit PR reviews now and let us know your thoughts.



