
Atsushi Nakatsugawa
March 11, 2026
1 min read
March 11, 2026
1 min read
共有
Faster AI code reviews with NVIDIA Nemotron 3 Superの意訳です。
TL;DR: NVIDIA Nemotron 3 Superは、CodeRabbitのセルフホスト型AIコードレビューにおいて、高い精度とより高速なスループットを実現します。
CodeRabbitは、AIコードレビューワークフローのコンテキスト収集および要約ステージにおいて、NVIDIA Nemotronファミリーのオープンモデルへのサポートを拡大し、Nemotron 3 NanoからNemotron 3 Superへアップグレードしたことをお知らせします。このアップグレードは、自社インフラ上でコンテナイメージを実行しているCodeRabbitのセルフホスト顧客向けに提供されます。
Nemotron 3 Superは、OpenAIやAnthropicのフロンティアモデルが、バグ修正のための深い推論とレビューコメントの生成を行う前の、コンテキスト収集および要約ステージを強化するために使用されます。Nemotron Superにより、そのレビュー基盤は大幅に強化されました。
Nemotron 3 Superのテストは、Nemotron 3 Nanoのサポートの後続として実施しました。以前の報告では、オープンモデルとフロンティアモデルの組み合わせにより、レビューワークフローの異なる部分を適切なモデルファミリーにルーティングすることで、特にPR要約フェーズにおけるコンテキスト収集の全体的な速度とコスト効率を向上できることを示しました。
Nemotron 3 Superの大きなコンテキストウィンドウとマルチトークン予測(MTP)の実行能力は、トークンを大量に消費するコンテキスト要約タスクに適しています。コードレビューワークフローがよりエージェント的で複雑になるにつれて、以下に示す2つの制約に直面していますが、Nemotron 3 Superはこれらの課題に対処するのに役立ちます。
コンテキストの爆発: マルチエージェントワークフローは、各ステップでツール出力、中間的な推論、リポジトリシグナルなどからのコンテキストが必要となるため、標準的なインタラクションよりも大幅に多くのトークンを生成します。長いレビューの過程で、このコンテキスト量の増加はコストを増大させ、目標のドリフトリスクをもたらします。
思考税: 複雑なエージェントタスクでは、各ステップで推論が必要ですが、すべてのサブタスクを大規模なフロンティアモデルにルーティングすると、パイプラインが遅く高コストになります。理想的な解決策は、利用可能な最も重いモデルにエスカレートすることなく、推論モデルをタスクのタイプに合わせたモデルの組み合わせになります。
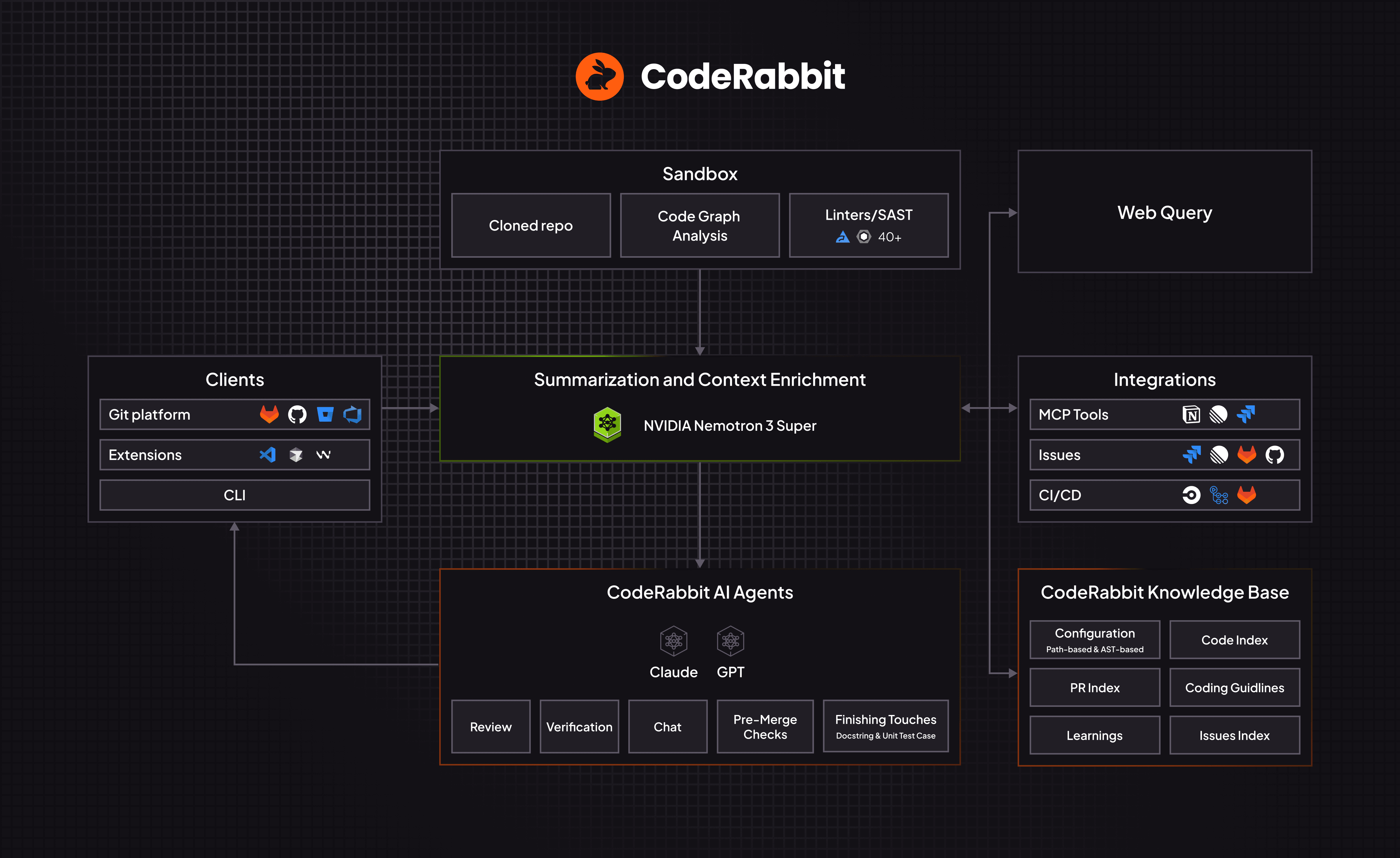
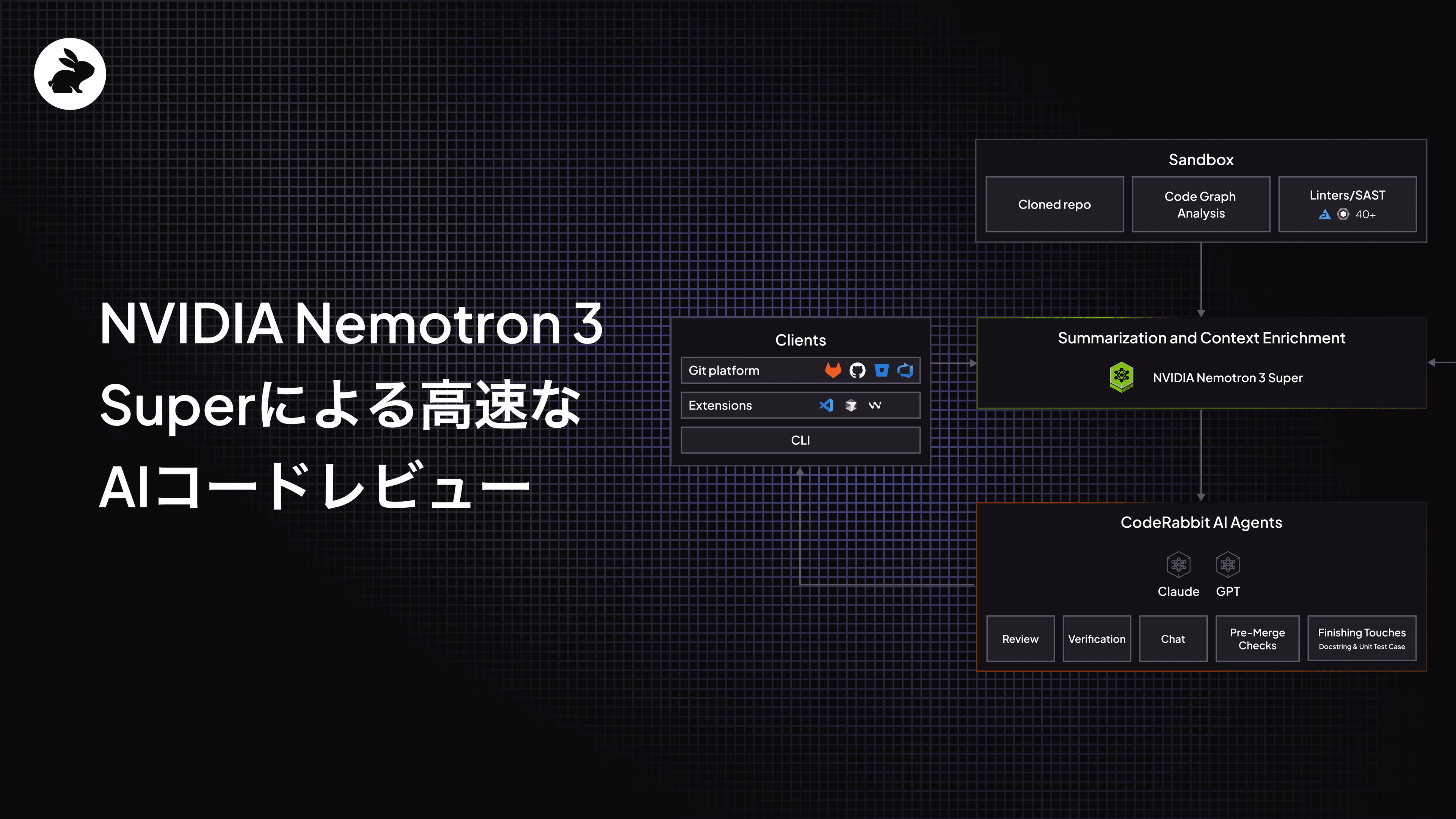
CodeRabbitアーキテクチャ:コンテキスト収集と要約にNemotron Superを使用
このコンテキスト構築ステージは、全体的なAIコードレビュープロセスの主力であり、レビューワークフロー全体を通じて反復的に複数回実行されます。NVIDIA Nemotron 3 Superは、高効率タスクに役立ち、その大きなコンテキストウィンドウ(100万トークン)と高速な速度によって大量のデータを収集し、コンテキスト要約と検索の複数回の反復を実行できます。コードレビューサイクル全体を通じてこれらの反復を何度も実行することで、レビューの質を高め、S/N比(シグナル対ノイズ比)を下げることができます。
プルリクエスト(PR)を開くと、CodeRabbitのコードレビューワークフローがトリガーされ、CodeRabbitがリポジトリのクローンからコードを分析する隔離された安全なサンドボックス環境から始まります。並行して、CodeRabbitは複数のソースからコンテキストシグナルを取得します。
コードとPRインデックス
Linter / 静的アプリケーションセキュリティテスト(SAST)
コードグラフ
コーディングエージェントルールファイル
カスタムレビュールールと学習内容
課題詳細(プラン詳細、Jira / Linear / GitHubチケット)
パブリックMCPサーバー
Web検索
このコンテキストの多くは、分析されるコード差分とともに、レビューコメントが生成される前にPR要約を生成するために使用されます。
CodeRabbitによって生成されたPR要約、Nemotron 3 Superを使用
要約はすべてのコードレビューの中心であり、レビューコメントで高いS/N比を実現するための鍵です。Nemotron 3 Superは、推論時に120億のアクティブパラメータを持つ1200億パラメータのオープンモデルです。そのハイブリッドMixture-of-Experts(MoE)アーキテクチャは、transformerレイヤーが推論を処理し、Mambaレイヤーがレビュー要約中のコンテキスト処理の大量で反復的な作業を処理します。これは、私たちのコードレビューにとって重要です。
複数のトークンを同時に予測することで、推論が有意に高速化され、レビュー要約が高速化されます。他のすべてのコードレビュータスクは、要約から派生します。レビュー要約が速いほど、全体的なコードレビューも速くなります。Nemotron SuperはNemotron 3 Nanoよりもはるかに高速なパフォーマンスを提供します。
Nemotron 3 Superは、外部ソース(Jiraチケット、ログ、プロジェクト要件ドキュメントなど)からのコンテキストを含む大規模なコードベースコンテキストを、長いタスク全体で状態を失わずに保持できます。
CodeRabbitは現在、レビューワークフローのコンテキスト要約部分にNemotron 3 Super(最初はセルフホスト顧客向け)をサポートしており、OpenAIとAnthropicのフロンティアモデルは隠れたバグの発見に集中します。顧客にとって、これは品質を損なうことなく、より高速なPR要約とコードレビューを意味します。
また、本日発表されたNVIDIAからの発表におけるNemotronファミリーのオープンモデルの拡大をサポートできることを嬉しく思っており、すべての業界にわたってAIコーディングの採用を加速させるために同社と協力できることを楽しみにしています。
セルフホスト型インフラでAIコードレビューを実行したい場合は、弊社チームにお問い合わせいただき、CodeRabbitのコンテナイメージへのアクセスを取得してください。


