

Atsushi Nakatsugawa
June 04, 2026
2 min read
June 04, 2026
2 min read
共有
Nemotron 3 Ultra makes the case for fast, open coding modelsの意訳です。
NVIDIA Nemotron 3 Ultraは、チャット画面向けに作られた新たなモデル、という印象ではありません。最初に問うべきなのは、リーダーボードで勝てるかどうかではなく、開発者がモデルを今使っている形に適合できるかどうかです。つまり、ターミナル、レビューパイプライン、コーディングエージェント、テスト生成ツール、そして雑然としたコンテキストの中でもモデルが処理を進め続ける必要があるワークフローの中で使えるかどうかです。
NVIDIAが、総パラメータ数約5,500億、トークンごとの有効パラメータ数が約550億の大規模なオープンモデルを公開しました。ただし、本当の訴求点は速度と制御性です。モデルが十分に高速であれば、開発者は処理の流れに関与し続けられます。システムはリトライできます。コーディング用ハーネスは、タスクが完了するまでモデルを動かし続けられます。
Ultraは、私なら「新しい最高のコーディングアシスタント」とは位置付けません。むしろ、オープンモデルが次のプロンプトを待つだけのチャットインターフェイスではなく、開発者向けシステムの内部で動く高速で制御可能なワーカーになっていく未来を示しています。
モデルが大きなループの一部として機能するワークフローでは、Nemotron 3 Ultraは特に重要になります。コードレビュー、テスト生成、リポジトリ調査、エージェント型コーディング、そしてチームが速度、制御性、モデルの実行場所を重視する社内自動化などです。

Nemotron 3 Ultraは、NVIDIAのNemotron 3ファミリーで最大のモデルです。このファミリーにはNano、Super、Ultraが含まれ、いずれもエージェント型AIアプリケーションを念頭に設計されています。Ultraはそのラインアップにおける大型の推論エンジンです。総パラメータ数は約5,500億で、疎なmixture-of-experts設計により、トークンごとに約550億パラメータが有効化されます。
最も分かりやすい比較対象は、同ファミリーの前世代の大規模モデルであるNemotron 3 Superです。
| Characteristic | Nemotron 3 Super | Nemotron 3 Ultra |
| ファミリー内での役割 | エージェント型ワークフロー向けの高スループット推論モデル | より複雑なコーディング、調査、エンタープライズワークフロー向けの最大のNemotron 3推論モデル |
| 総パラメータ数 | 120B | 550B |
| 有効パラメータ数 | トークンごとに12Bが有効 | トークンごとに55Bが有効 |
| アーキテクチャ | Hybrid Mamba-Transformer MoE | Hybrid Mamba-Transformer MoE |
| エキスパート設計 | Latent MoE | Latent MoE |
| コンテキスト長 | 最大1Mトークン | 最大1Mトークン |
| 効率化機能 | マルチトークン予測とNVFP4による学習・デプロイ経路 | マルチトークン予測とNVFP4指向のデプロイ経路 |
| 最適な用途 | 大量のエージェント型ワークフロー、コーディング、計画、ツール利用 | 速度、スケール、より強い推論を同じループ内に置く必要がある、より要求の高い開発者向けワークフロー |
より平易に言えば、これは単に巨大化したdense Transformerではありません。Ultraは、トークンごとにネットワークの一部だけを有効化し、長いコンテキストを現実的に扱い、開発者が遅いバックグラウンドバッチジョブのように扱うのではなく、対話的に使えるだけの速度でトークンを生成するように作られています。

発表時の数値を見ると、Ultraは強い位置にあります。Artificial Analysisは、Intelligence IndexでNemotron 3 Ultraを48と報告しました。その時点のスナップショットでは、Gemma 4 31B、Nemotron 3 Super、gpt-oss-120bを上回り、米国のオープンウェイトモデルとして首位でした。Kimi K2.6は54でまだ上位にあるため、Ultraがオープンモデルの最前線全体を制したという主張ではありません。主張の中心は、到達している知能レベルに対して非常に高速だという点です。
Artificial Analysisは、プレリリース版のDeepInfraエンドポイントで、出力が毎秒300トークンを超えたことも報告しています。開発者にとって有用なのは、この速度です。コーディングではレイテンシが行動を変えます。モデルが遅ければ、依頼して放置する形になります。高速であれば、流れに関与し続け、追加質問を投げ、複数回試行し、エージェント型ハーネスに処理を進めさせられます。
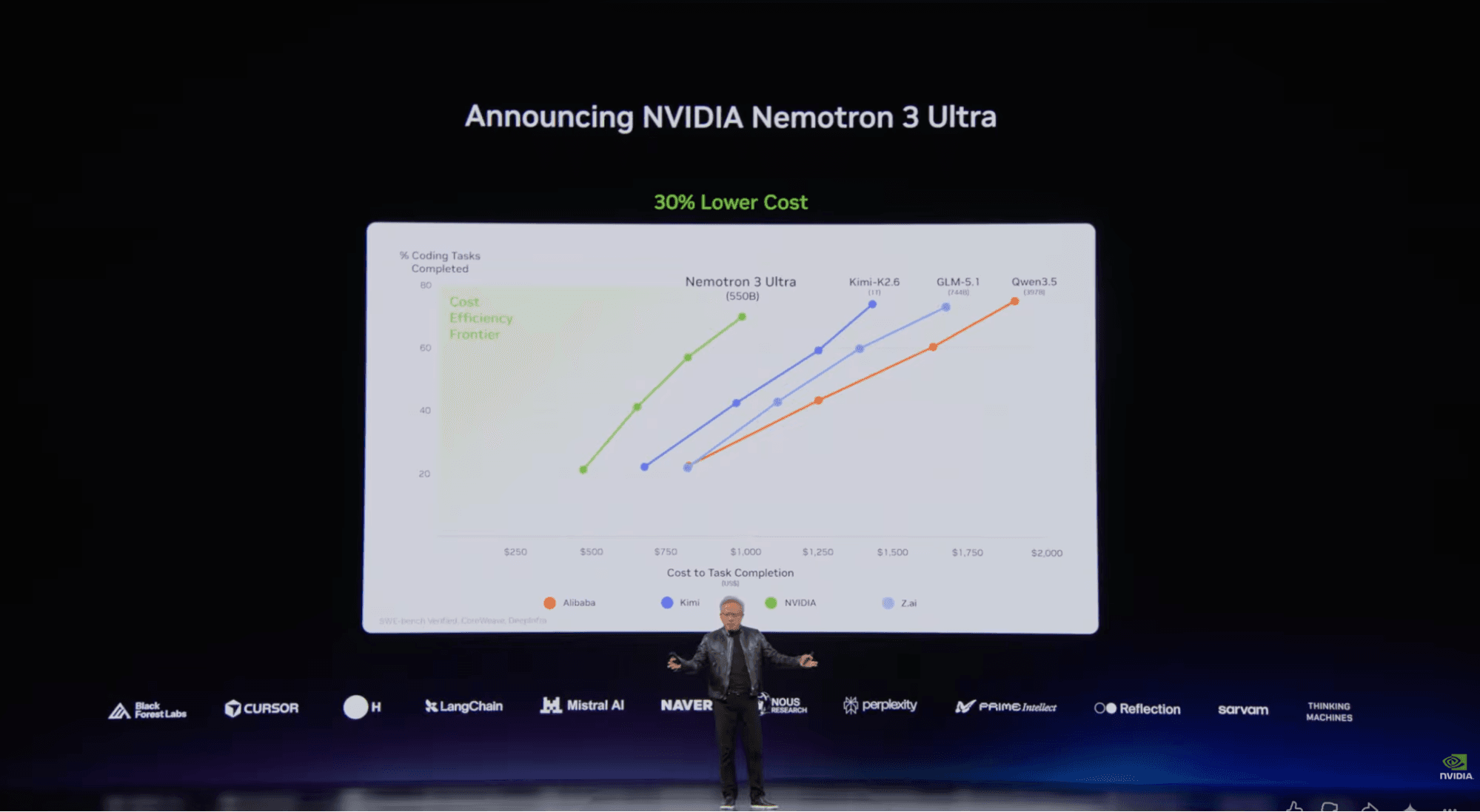
Nemotron 3 Superは、NVIDIAがエージェント型ワークフロー向けの有力なオープンモデルを構築できることをすでに示していました。Ultraは、そこから2つの方向でさらに進んでいます。
第一に、はるかに大規模です。Superは総パラメータ数が約1,200億で、有効パラメータ数は約120億です。Ultraは総パラメータ数が約5,500億、有効パラメータ数が550億に増えています。この追加されたスケールは、NVIDIAや初期テスターの語り方にも表れています。小さく効率的な補助モデルではなく、選択されたワークフローではプロプライエタリな最先端システムから一部の作業を担えるモデルとして語られています。
第二に、Ultraは開発者向けハーネスをより直接意識して学習・評価されているように見えます。NVIDIAは、Superがエージェント型ハーネスで優れていることが分かった一方、Ultraはそれらのハーネスを念頭に置いて構築されたと述べています。コーディングツールにとって、これは要件を変えます。OpenCode、OpenHands、Kilo Code、Continue、または社内コードレビューループでうまく動くモデルには、質問に答える以上のことが求められます。ツールプロトコルに従い、長いコンテキストを扱い、繰り返しのプロンプトの中で前進し、詰まったときに復帰する必要があります。
Ultraの挙動は、その目標に合っています。このモデルは高速で、直接的で、過度に冗長ではなく、多くの確認を求めにくい傾向があります。これはハーネス内では強みになり得ますが、タスクが明示されていない要件に依存する場合は弱みになります。明示的な指示を与えることで性能を引き出しやすくなります。最適なメンタルモデルは、ClaudeスタイルのプロンプトよりもCodexスタイルのプロンプトに近いものです。タスクを明確に書き、受け入れ条件を示し、期待する出力形式を指定します。
CodeRabbitの社内ベンチマークは、発表時のグラフよりも、さらに地に足のついた見方を提供します。このベンチマークでは、基準となるレビューモデル群とNemotron 3 Ultra構成を、105件の評価問題で比較しています。問題は比較的簡単なものから、より難しいレビュータスクまで含まれます。評価では、検証、重複排除、強めのフィルタリングを行った後の、パイプライン通過後の最終コメントを使用しています。ジャッジはgpt-5.1で、推論はmedium、冗長性はlow、single mode、3票で判定されています。
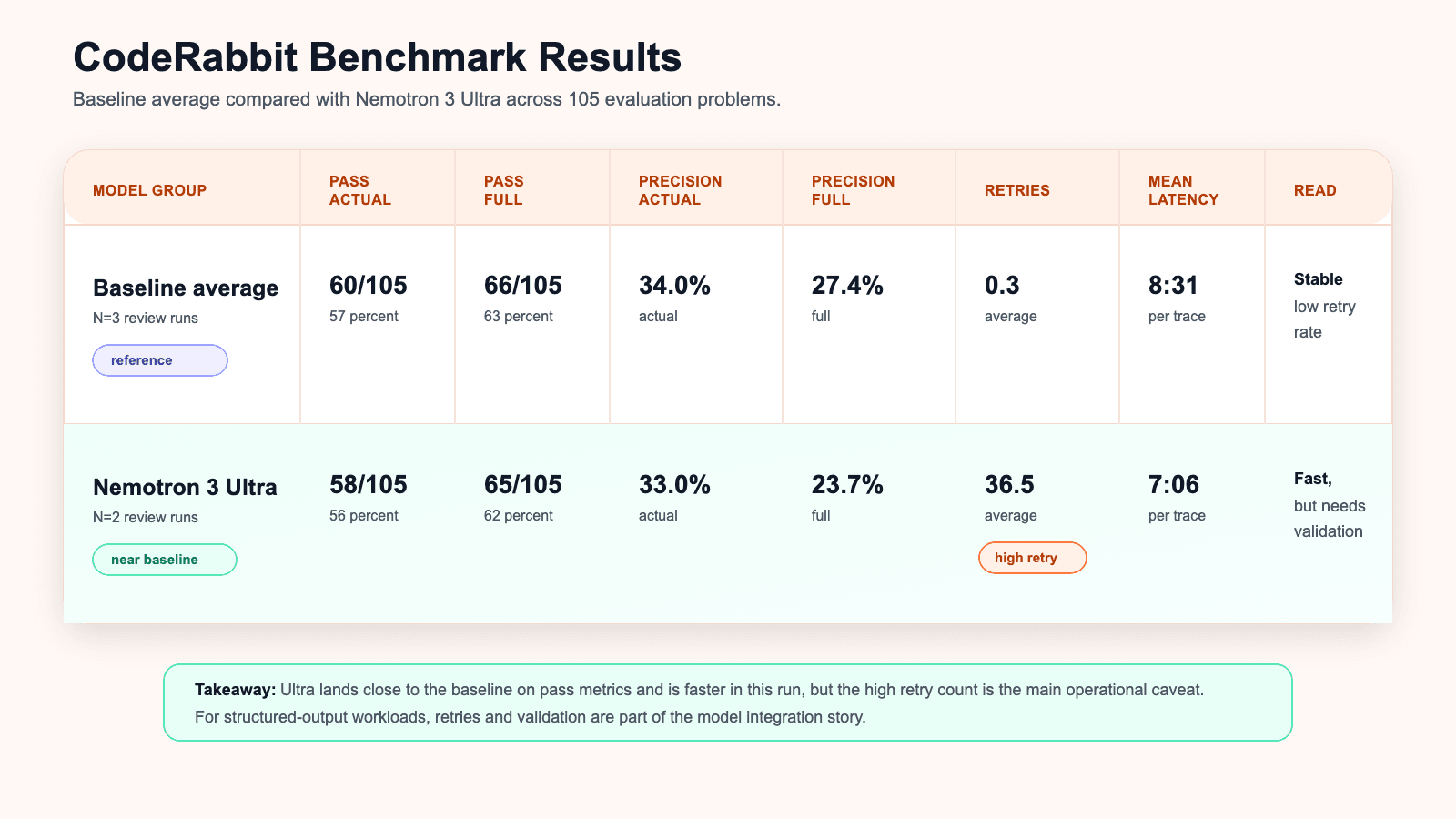
主要な結果は近い値です。
肯定的に読むなら、このレビュー負荷では、Ultraはpass指標で基準モデルとほぼ同じ範囲にいました。問題を見つけ、レビューパイプラインを通過し、CodeRabbitらしい有用なコメントを生成しました。
注意点は信頼性です。このモデルはリトライ率が高い結果でした。ベンチマーク概要では、Ultraの実行では平均36.5回のリトライが示されており、基準モデルの0.3回と対照的です。リトライ分布では、約66パーセントがscratchpadのみだったと記されています。運用上、このモデルは必要な出力マーカーや最終的な構造化出力を生成する前に、自発的に停止してしまうことがあります。プロンプトを変えずにリトライすると成功することが多いため、能力はあると考えられますが、初回試行で完了する挙動は、無視できるほど安定しているわけではありません。
CodeRabbitのデータから得られる実務上の知見は明確です。Nemotron 3 Ultraは作業をこなせますが、構造化出力タスクでは検証とリトライロジックで包むべきです。
レイテンシについても興味深い兆候があります。このベンチマークでは、Ultraの実行はレビュー全体のトレース平均レイテンシが7分06秒で、基準モデルの8分31秒と比較されています。この特定のレポートでは巨大な差ではありませんが、Ultraの実行は大きなリトライ負荷を抱えながらも、時間面で競争力を保っていました。NVIDIAのUltraに関する説明は、同じ考えに何度も戻っています。モデルが十分に高速であれば、複数回の試行でも、より遅く慎重な1回の試行に勝てる場合がある、という考えです。
コスト面の話は、このベンチマークではそれほど単純ではありません。この表では、Ultraの実行に対して報告された総コストは基準モデルより高くなっています。ただし、これは過度に一般化すべきではありません。社内フォールバック率、ホスト型エンドポイントの価格、リトライ挙動が、ローカルな実験結果を大きく左右し得るからです。NVIDIAとArtificial Analysisが公開している話の中心は、完了あたりのコストとスループットです。CodeRabbitの結果が示しているのは、より限定的な内容です。このベンチマークでは、品質は近く、速度は競争力があり、信頼性を制御するループには改善の余地がある、ということです。
Nemotron 3 Ultraの最も有力なユースケースは、「すべてのコーディングモデルを置き換えること」ではありません。「明示的な指示と外部チェックを組み合わせて、有用な開発作業を大量に高速に実行すること」です。
有望に見える用途は次のとおりです。
NVIDIAは、有用な例も共有しています。UltraはOpenCode内で複数の論文を読み、それらをまたいで推論するために使われました。これは博士課程レベルのコーディング課題ではありませんが、速度がワークフローを変える、まさに日常的な開発者タスクです。ターミナル内にとどまり、モデルの進行を見ながら、制御し続けられます。
CodeRabbit型の作業では、このモデルは比較的簡単なレビュータスクや中程度の難易度のレビュータスクでも特に興味深く見えます。これらも価値のあるレビューです。システムには、実務的な問題を見つけ、明確に説明し、毎回より高価な最先端モデルを待たずに大量のレビュー出力を生成することが求められます。
Ultraには構造が必要です。コーディングや開発者向け自動化に使う場合、自由形式のチャットモデルとして扱い、ワークフローを推測してくれることを期待すべきではありません。ハーネスやチェックリスト、停止条件、出力検証を与えます。
実務上の指針は次のとおりです。
このモデルは、チームがベンチマークをどう考えるべきかも変えます。純粋な一発勝負のベンチマークは、現実のプロダクトループでリトライが許される場合、Ultraを過小評価する可能性があります。リトライを無視するベンチマークは、プロダクトが初回の厳密なフォーマット遵守を必要とする場合、Ultraを過大評価する可能性があります。適切な指標は、おそらく利用可能な完了までの時間に近いものです。品質、リトライ、レイテンシ、コストをまとめて測る必要があります。
Nemotron 3 Ultraは、開発者向けのオープンモデル公開として非常に興味深いものの一つです。知能だけを追っているわけではなく、使えるスループットを追っているからです。
このモデルは大規模で、オープンで、高速です。公開ベンチマークでは、米国のオープンウェイトモデルの知能面で上位に位置しつつ、出力速度では多くの同種モデルを大きく上回っています。CodeRabbitのベンチマークは、より冷静な見方を加えています。Ultraは強力なレビュー基準に近い性能を出せますが、構造化出力の信頼性については、現時点ではリトライと外部検証が必要です。
評価は一面的ではありません。厳密なフォーマットを初回で必ず成功させるモデルがほしいなら、Ultraはまだ最も安全なデフォルトではありません。一方、ハーネスが検証してリトライし、作業が完了するまでモデルに処理を続けさせられるエージェント型の開発者システムを構築しているなら、Ultraはかなり有力になります。
コーディングチームにとって、より大きな論点は、Nemotron 3 Ultraが好みのチャットモデルを置き換えるかどうかではありません。オープンで高スループットなコーディングエージェントが、現実的に感じられる段階に入りつつあるのかどうかです。
今すぐCodeRabbitのPRレビューで試して、感想をお聞かせください。


