Aleks Volochnev
February 28, 2026
11 min read
February 28, 2026
11 min read
Share
Cut code review time & bugs by 50%
Most installed AI app on GitHub and GitLab
Free 14-day trial
Over the past few months, one refrain has been heard consistently in open source communities: “AI slop.” It shows up in LinkedIn discussions from CEOs who rarely complain publicly.

It shows up in Reddit threads, where users only think AI slop has become worse over the past few months.
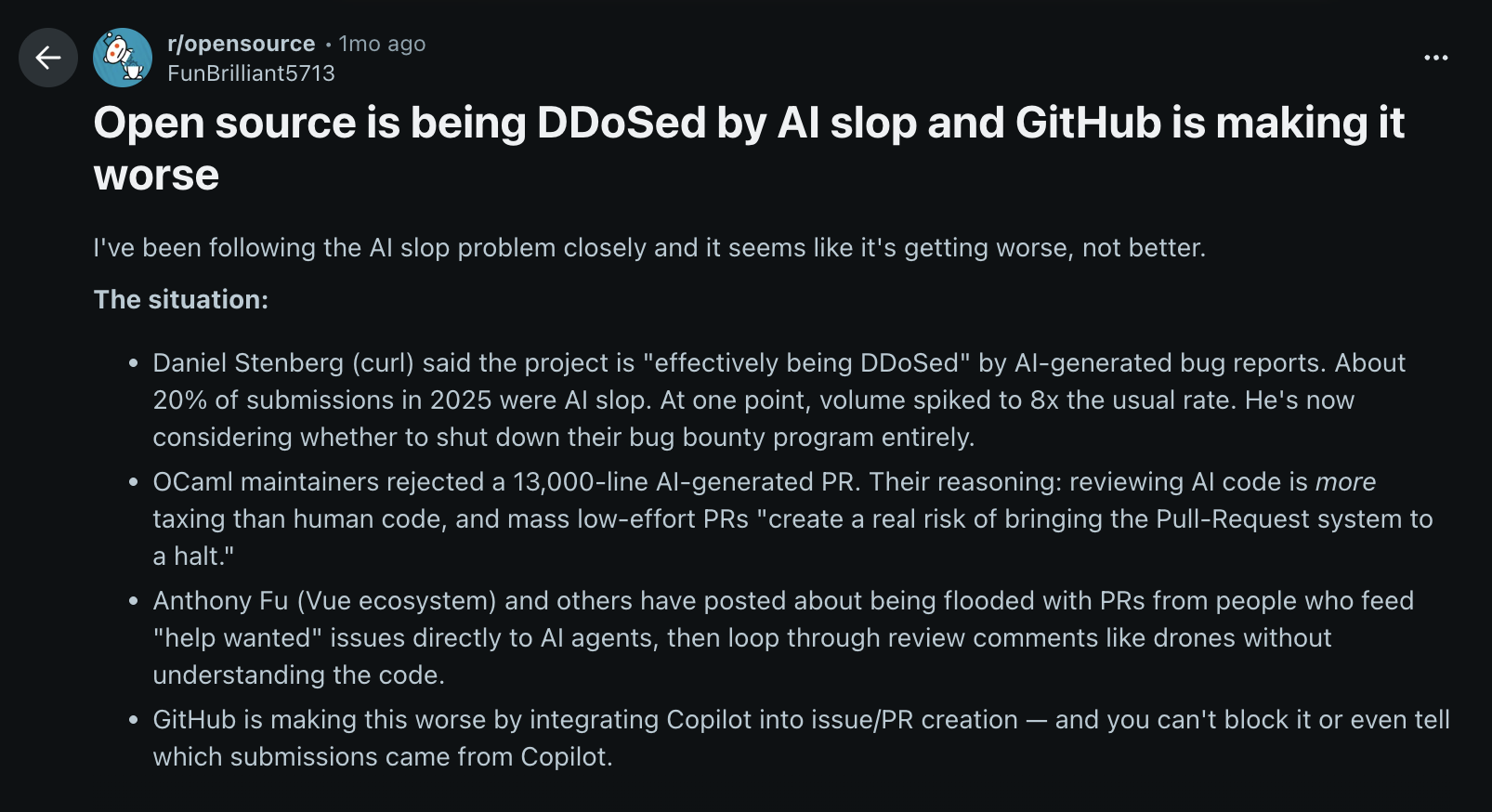
In Twitter posts from popular OSS projects who have begun automatically closing pull requests from external contributors.
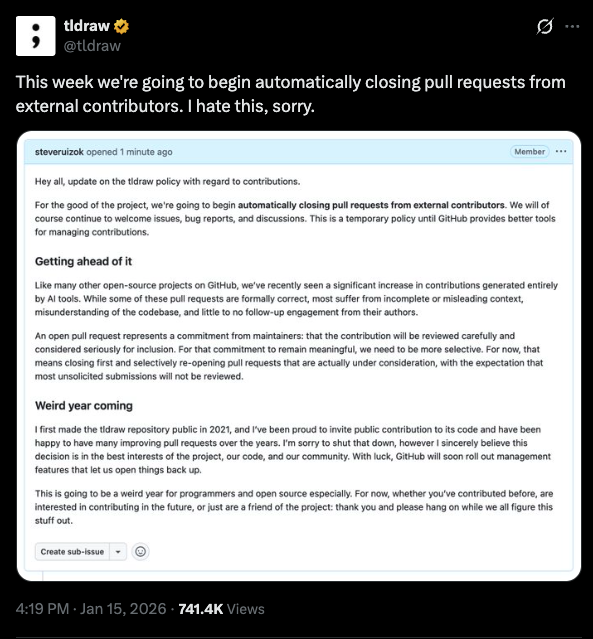
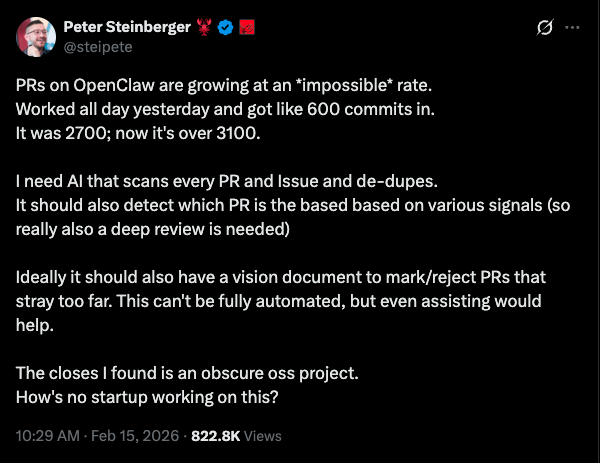
The theme is consistent: projects are being flooded with AI-generated pull requests that merge cleanly but don’t actually work.
Some maintainers are adding stricter contribution templates. Others are asking for smaller PRs. A few have temporarily limited new contributors just to regain control of their review queues. This isn’t an anti-AI backlash. Most of the people raising these concerns use AI themselves.
Even a prominent figure like Peter Steinberger, the creator of the popular AI agent OpenClaw (which was recently acquired by OpenAI), is struggling with the overwhelming volume of PRs. Despite his own heavy reliance on AI tools, he has publicly requested a better solution to manage the pace of incoming contributions.
As a maintainer of open source projects, I integrated AI into my coding process. Initially, this combination felt ideal as development gained momentum, contributors submitted fixes faster, and issues were addressed more consistently.
The shift in open-source development felt invigorated; problems that once took months were now resolved in hours. This speed was beneficial when AI augmented human judgment.
However, as the focus moves toward fully automated agents, a crucial element is diminishing. The issue with many of these automated pull requests isn't technical syntax, but a failure of judgment.
What I didn’t expect was how much time I would start spending reviewing pull requests. That wasn’t because contributors suddenly got worse, or because AI made people careless. Writing code stopped being the hard part. Open source has always depended on the hard parts to act as a natural filter on what gets proposed, reviewed, and ultimately merged.
Surveys like Stack Overflow’s Developer Survey show that a large majority of developers (80%) already use, or plan to use, AI coding tools. You don’t need a report to feel that shift, though, you can see it immediately in active repositories.
Pull requests arrive faster, they tend to be larger on average, and they often carry the unmistakable shape of something generated from a single prompt or a short back-and-forth with a model. That isn’t a criticism, I use AI tools every day myself and I would be lying if I said I wanted to go back to the way things were before.
This is simply what happens when contribution becomes cheap. The problem many open source maintainers are running into is that reviewing those contributions did not get the same speed boost and it has become more cognitively demanding.
I have seen pull requests that introduce a brand-new abstraction layer to solve what was previously a five-line change, complete with interfaces, helpers, and configuration flags that technically work but dramatically increase complexity.
Nothing is “wrong” in the obvious sense. The surface-level checks-passing tests and a green CI-suggest no obvious errors. However, the reviewer's burden increases significantly; they must now decipher not only what changed, but also the rationale behind the specific implementation chosen and whether it subtly contradicts long-standing architectural decisions.
Reviewing AI-generated code is strange because it often looks correct at first glance. The formatting is clean, naming is reasonable, and the logic flows in a way that feels intentional. Yet, you find yourself slowing down, because something does not quite sit right.
You start asking questions that are hard to answer quickly.
Why does this abstraction exist at all?
Why does this function do three things instead of one?
Why does an approach technically work but feel fragile under real-world conditions?
A frequent issue I've observed is with error handling in AI-generated code. For instance, I've reviewed changes where the AI catches and logs every conceivable exception. While this appears robust on the surface, in reality, it can mask critical failures that other parts of the system rely on to be visible. The change functions correctly in isolation but introduces subtle flaws by violating system-wide assumptions.
Catching that kind of issue requires knowing how downstream components expect failures to propagate, which is rarely written down. Those are not questions a linter answers, and they are not always questions a contributor can explain either, especially when they do not fully own the context behind the change.
Most open source projects rely on a large amount of implicit knowledge that never makes it into documentation. There are old design decisions buried in issues from years ago, conventions enforced socially rather than technically, and trade-offs that only make sense if you remember why something was done a certain way in the first place.
AI does not know any of that unless someone teaches it and contributors often do not know it either. That gap is where much of today’s review friction lives.
Research on open source sustainability has shown for years that a tiny percentage of contributors do the majority of review work. So, in open source, this kind of review almost always falls on the same small group of people. You see the same names over and over again on merged pull requests.
Maintainer burnout did not start with AI, but AI made it more visible by removing many of the buffers that once kept it manageable. More pull requests come in. Fewer of them are obviously wrong. Each one requires more careful mental simulation to feel confident it will not cause problems later. That often means scrolling through files, replaying edge cases in your head, and asking yourself what you are about to miss this time.
It is slow, quiet work, and does not scale well.
As the effort required for review outpaces the availability of reviewers, projects suffer a gradual decline rather than an abrupt failure. The symptoms include slower responses and accumulating unresolved issues. This eventually discourages contributors, who cease participation due to the lack of timely feedback.
What is interesting is that many projects have started adapting without making a big announcement about it. You see stricter automated checks appear, clearer expectations for pull request descriptions, and more effort spent validating changes earlier in the process, before a maintainer ever looks at them.
Reviews are moving earlier in the workflow not because maintainers want to be gatekeepers, but because human attention is limited and expensive. It makes more sense to spend it on intent and design than on catching avoidable mistakes.
AI didn’t break open source. It exposed what was already straining under the surface: reading code is harder than writing it, especially when AI writes most of it.
The real shift wasn’t just faster generation. It was volume. Suddenly, maintainers weren’t reviewing a handful of thoughtful pull requests each week. They were reviewing AI-generated diffs at a pace no human brain signed up for. Writing got easier. Reviewing got exponentially harder.
That’s where AI code reviews started to make sense to me - not as a vague “AI assistant,” but as an always-on reviewer that runs before a human ever has to burn cognitive energy on a PR.
When I started using CodeRabbit on my open source projects, it caught the obvious things immediately: off-by-one errors in pagination logic, missing error handling around external calls, subtle edge cases that only fail under specific configurations, and security issues that would have been painful to debug after a release. It flagged missing tests that technically “worked” but weren’t defensible. It forced contributors including myself to clean up code before asking for human reviewer time.
Instead of spending my energy scanning for logic bugs or basic security issues, I could focus on intent.
Does this align with the project’s direction?
Does this abstraction make sense long term?
Is this the right tradeoff?
The AI handled the mechanical correctness checks so humans could stay strategic.
In my experience, automating feedback early in the pull request process speeds things up and reduces review cycles. When contributors know their PR will get AI code review feedback instantly, they submit smaller changes, write clearer descriptions, and fix obvious issues before a maintainer ever looks at it.
The turning point for me was realizing the reviews weren’t just “nice to have.” They were protecting my reputation. If AI was writing a growing share of my code, I needed AI reviewing it with the same rigor, before it hit the repo.
That’s, ultimately, why I joined CodeRabbit.
The quality of the reviews, the codebase awareness, the ability to run checks locally in the IDE before pushing - it solved the exact bottleneck I was feeling in open source. AI code generation scaled output. AI code reviews scaled judgment.
Open source didn’t need less AI. It needed AI in the right place in the workflow.
And when reviews move left…before the pull request, before the human fatigue sets in - maintainers get their time back for what actually matters: design, direction, and shipping software that doesn’t wake you up at 2 a.m.
Open source does not collapse because of bad code. It collapses because a handful of maintainers end up reviewing everything.
AI made that imbalance worse. Contributors can now generate fixes, refactors, and feature PRs in minutes. Review still happens at human speed. The result is predictable: more notifications, longer queues, and maintainers spending nights and weekends doing unpaid triage.
Burnout in open source rarely looks dramatic. It looks like this:
PRs sitting unreviewed for weeks.
Maintainers closing issues with “won’t fix” because they simply do not have time.
Fewer thoughtful reviews and more rubber stamps just to clear the backlog.
Talented maintainers quietly stepping back.
That is not a tooling problem. It is an attention problem.
CodeRabbit helps by acting as a first-pass reviewer that never gets tired and never rushes through a diff. It reviews every pull request line by line, checks for logic errors, edge cases, security risks, and cross-file impact, and flags issues before a human even opens the tab.
For maintainers, that changes the shape of the work:
Instead of scanning for obvious bugs, you focus on architecture and intent.
Instead of manually checking for missed requirements, you validate higher-level decisions.
Instead of absorbing every small fix yourself, contributors address AI feedback before requesting review.
CodeRabbit is committed to supporting open source software, having pledged $1 million in sponsorships. We rely heavily on open source technology and fundamentally believe that CodeRabbit's AI is a tool to assist, not replace, the vital role of open source maintainers. It absorbs the repetitive, error-prone parts of review so humans can spend their limited energy where it matters most.
Open source survives on people. If AI is going to increase code volume, we need something equally consistent helping with review. Otherwise, the cost stays concentrated on the same few maintainers until they burn out.
If you maintain an open source project and your review queue keeps growing, try CodeRabbit on your next repository. CodeRabbit is free for open source. Every maintainer, contributor, and community can use our platform to cut through PR noise, automate code quality checks, and free up more time for meaningful contributions.