Atsushi Nakatsugawa
January 09, 2026
3 min read
Share
Cut code review time & bugs by 50%
Most installed AI app on GitHub and GitLab
Free 14-day trial
How to evaluate AI code review tools: A practical frameworkの意訳です。
ベンチマークは、常に客観性を約束してきました。
複雑なシステムをスコアに落とし込み、競合を同じ土俵で比較し、数値に語らせるという発想です。
しかし実際には、ベンチマークが抽象的な意味での「品質」を測ることはほとんどありません。
測っているのは、ベンチマーク設計者が何を重視するかを選び、そのテストがどのような制約やインセンティブの下で構築されたか に過ぎません。
データセットやスコアリング基準、プロンプト、評価ハーネスのいずれかを変えるだけで、結果は大きく変わります。
これはベンチマークが無意味だということではありません。
ただし、極めて操作可能であり、しばしば誤解を招く という事実は意味します。
データベース性能ベンチマークの歴史は、非常に分かりやすい教訓です。
標準化されたベンチマークが普及すると、ベンダーは実運用のワークロードではなく、テストそのもの に最適化し始めました。
クエリ計画は手動でチューニングされ、キャッシュ挙動はベンチマークの前提を突くように設計され、
本番チームが現実的に採用であろう設定が使われるようになりました。
やがて多くのエンジニアは、ベンチマーク結果を信頼しなくなり、
それを「指標」ではなく「マーケティング」として扱うようになりました。
AIコードレビューのベンチマークも、同じ道をたどりつつあります。
モデルやツールが、厳選された課題セット、合成PR、狭く定義された正確性基準で評価されるようになるにつれ、
ベンダーは(意図的であれ無意識であれ)実際のプロダクションコードレビューの複雑で文脈依存かつ高リスクな現実 ではなく、
ベンチマークに最適化する方法を学んでいきます。
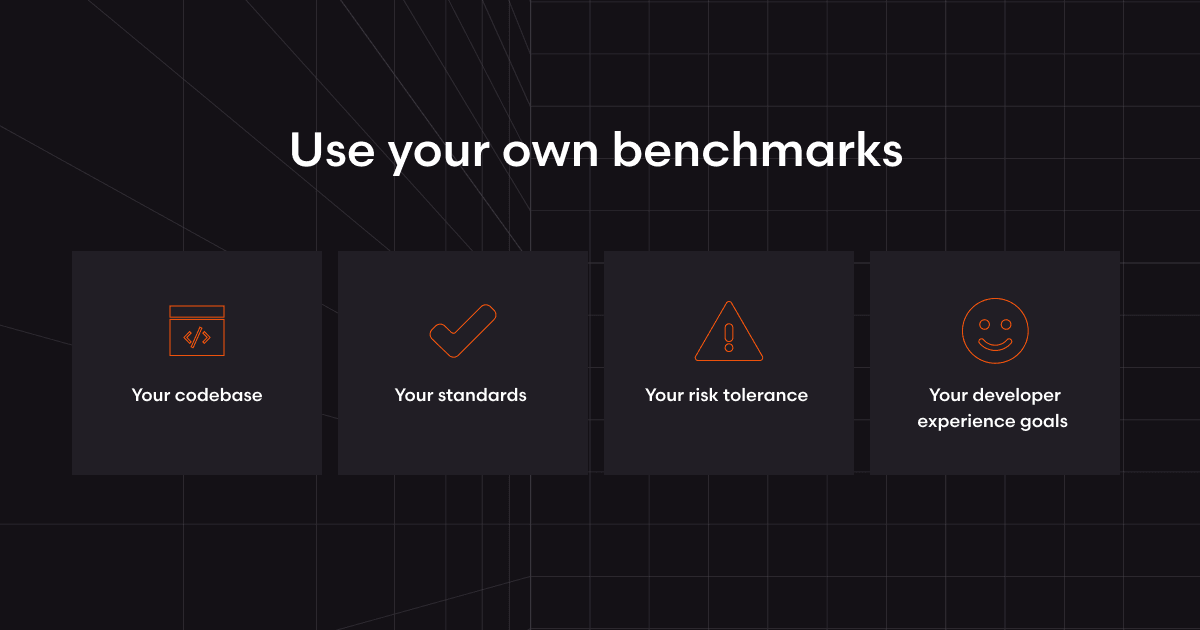
AIコードレビューツールを評価する正しい方法は、誰かが定義した「レビュー品質」の基準を追いかけることではありません。
次の要素を反映したプロセスを設計することです。
あなたのコードベース
あなたの基準
あなたのリスク許容度
あなたの開発者体験の目標
以下は、CodeRabbit を他のツールと比較する際に、私たちが推奨しているフレームワークです。
ベンダーニュートラルであり、社内で実装できます。
さらに重要なのは、何を測るべきかを押し付けたり、私たちが有利になる前提を埋め込んだりしていない 点です。
重要なのは、あなたにとって何が最も大切かです。

データセットや指標を組み立てる前に、
何を重視するのかを明確に定義すること が重要です。
お客様がよく設定する目的の例は次のとおりです。
本番流出バグの削減:コードレビュー漏れに起因する本番インシデントの減少。
長期的な保守性の向上:「謎のバグ」や脆弱な箇所を減らし、可読性・モジュール性・テスト容易性を促進。
スループットの維持または向上:マージまでの時間を大きく増やさず、低価値なノイズでレビュアーを圧迫しない。
エンジニアリング基準の引き上げ:社内ガイドラインやベストプラクティスを一貫して適用。
チームごとに、これらの重み付けは異なります。
たとえば、セキュリティ重視のバックエンドチームと、UI中心のフロントエンドチームでは評価方法は異なります。
評価手法には、その違いを織り込むべきです。
ベンチマークは、さまざまなコードベースから抽出されたサンプルPRを使用します。
しかし、それでは あなたのコードベース や あなたが使っている言語 に対する性能はほとんど分かりません。
AIコードレビューツールを評価するためのデータセットは、次のように構築します。

少なくとも100件程度のPRを目安に、PRの種類や言語、フレームワーク、傾向、サービスに多様性を持たせてください。
以下のPRタイプを必ず含めます。
バグ修正
機能追加
リファクタリング
インフラ/設定変更
テストのみの変更
ツールが得意だと分かっているPRを選別してはいけません。
目的はデモではなく、代表性 です。

データセットには、人間のレビューで過去に発見されてきた次のようなPRを含めます。
致命的な正確性バグやリグレッション
セキュリティ問題(インジェクション、認証、データ漏えい)
パフォーマンスや並行性の問題
保守性の問題(複雑性、重複、不適切な抽象化)
テストの不足や弱さ
可読性に影響するドキュメントや命名の問題
バグトラッカーやインシデントの事後分析を活用し、マージ後に問題となったPR、すなわち「本来レビューで拾えたはずの失敗例」を見つけてください。

各PRについて、次のソースから問題候補を集めます。
元のPRにおける人間のレビューコメント
後からそのPRに起因すると判明したバグやインシデント
評価実行時に各ツールが検出した問題
コメントは表現単位ではなく、根本的な問題単位 でまとめます。
複数のコメントが同じ原因を指している場合もあります。
各問題について、重要度(Critical / High / Medium / Low)と妥当性(自社基準で本当に問題か)を付与します。
整合性を保つため、次のような文書化されたガイドラインを作成してください。
Critical:セキュリティ脆弱性、データ損失、障害
High:クラッシュ、重大な機能バグ、データ不整合
Medium:即時障害にはならない正確性問題、重大な性能劣化
Low:リファクタ、スタイル、可読性、テスト品質、ログ/メトリクス、いわゆるコードスメル
ドメインごと(バックエンド、フロントエンド、インフラなど)に、最低2名のシニアエンジニアで評価し、一致度を測定します。
意見が分かれた場合は議論して解決し、難しいケースは文書化します。
これは手間ですが、評価を自社のエンジニアリング文化に合わせる最重要ポイント でもあります。
長期的な保守性や技術的負債を重視している場合(ほとんどの組織がそうです)、低重要度の問題を指標から除外すべきではありません。
代わりに次を行います。
重要度ごとに指標を報告する
必要に応じて重み付きスコアを定義する(例:Critical=4、High=2、Medium=1、Low=0.5)

あなたにとって本当に重要な指標は何でしょうか。
多くの場合、ベンダー定義のデータセットは全体像を示さず、自社ツールが得意な点に基づいて設計されており、弱点を隠すように作られています。
実務では、少なくとも次の3つの指標グループが必要です。
コードレビューツールの検出能力を定量化する方法はいくつかあります。
重要度別リコール
Recall@Critical、Recall@High、Recall@Medium、Recall@Low
重視している問題のうち、どれだけを検出できたか
適合率(コメント品質)
ツールが出したコメントのうち、実際に妥当な問題はどれくらいか
新規発見を不当に減点しないため、未一致コメントをサンプリングし、人間が妥当性を判断するのも有効
新規問題の発見
人間が最初にラベル付けしていなかった実在の問題を、どれだけ発見できたか
新しい問題クラスを発見できるツールは、レビュー文化そのものを変える可能性を秘めています
開発者が好み、実際に使われるツールであることが重要です。
コメント量と密度
PRあたり、100LOC(Line of Code。コード行数)あたりのコメント数
重要度やカテゴリごとの分布
ノイズ
人間レビューとの重なり
人間が見つけた問題のうち、ツールも検出した割合
人間が見逃しがちだった問題を、ツールが検出した割合
アンケートベースのUX
例:
「このPRで時間短縮になりましたか?」
「次のPRでも使いたいですか?」
ベンチマークはピンポイントの比較に過ぎず、生産性や文化への影響は分かりません。
最良の比較方法は、4〜8週間程度のパイロット運用です。
マージまでの時間
レビュアー負荷
PRあたりの人間コメント数
形だけのLGTMレビューの変化
本番流出バグ

最も信頼できる評価は、制御されたオフライン評価 と 実運用パイロット を組み合わせることです。
同一の過去PRセットに対して、各ツールを実行し、すべてのコメント(インライン、サマリー、差分外)を収集します。
その後、ゴールデンイシューと、公開されたプロンプトや閾値を持つLLMマッチャー、またはファイル/行+意味チェックによるルールベースマッチングを使います。
あとは、追跡したい指標を計算するだけです。
重要度・問題タイプ別の適合率/リコール
コメント量と分布
各ツールについて、いくつかのチームやプロジェクトを選び、通常運用で4〜8週間使用します。
以下を測定します。
マージまでの時間やPRスループット
開発者満足度と有用性の認識
実際の問題検出(上記と同様のサンプリング)
可能であれば、ツールあり/なし、ツールA/ツールBを比較するA/B形式の実験を設計してください。
良いツールの指標とは何でしょうか。
私たちの考えでは、狭い精度よりも、カバレッジと設定可能性が重要 です。
つまり、最初から問題検出数が少ないツールよりも、ノイズは多くても 後から調整できるツール の方が優れています。
コードレビューは企業ごとに異なり、ある会社ではノイズに見えるコメントが、別の会社では技術的負債削減に不可欠な場合もあります。

コメントが少なく、すべて正しいツールは精度が高く見えますが、リコールが極端に低い可能性があります。
それは実質的に「LGTMボット」です。
必ず、実際に何を検出しているかを確認してください。
私たちは次のようなツールから始めるべきだと考えています。
バグ、セキュリティ、性能、コードスメル、保守性、技術的負債まで幅広く検出する
技術的に根拠のある詳細なコメントを出す
その上で 自社向けに調整 します。
不要なカテゴリをオフにする
重要度閾値や抑制ルールを調整する
リポジトリ/ディレクトリ単位でポリシーを設定する
ベンチマークは出発点にはなりますが、結論ではありません。
小規模で厳選されたデータセット、不透明な評価者、主観的な重要度スキーム、そして競合ツールを善意で設定すると信じる前提の上に成り立つ場合、本当に重要なことを測らないまま、精度があるかのような安心感を与えてしまいます。
自社のコードと基準に基づいた、より厳密で透明性の高い評価には多少の労力が必要です。
しかしその分、短期的な品質向上だけでなく、コードベースの長期的な健全性を高めるAIレビューツールを選んだという確信を得ることができます。
CodeRabbit があなたのコードベースでどう機能するか気になりますか?
今すぐ無料トライアルをお試しください!