
CodeRabbit is now in the Claude Marketplace!Learn more

David Loker
January 09, 2026
8 min read
January 09, 2026
8 min read
Share
Cut code review time & bugs by 50%
Most installed AI app on GitHub and GitLab
Free 14-day trial
Giving users a dropdown of LLMs to choose from often seems like the right product choice. After all, users might have a favorite model or they might want to try the latest release the moment it drops.
One problem: unless they’re an ML engineer running regular evals and benchmarks to understand where each model actually performs best, that choice is liable to hurt far more than it helps. You end up giving users what they think they want, while quietly degrading the quality of what they produce with your tool with inconsistent results, wasted tokens, and erratic model behavior.
For example, developers may unknowingly pick a model that’s slower, less reliable for their specific task, or tuned for a completely different kind of reasoning pattern. Or they might choose a faster model than they need that won’t comprehensively reason through the task.
Choosing which model to use isn’t a matter of personal taste… It's a systems-level optimization problem. The right model for any task depends on measurable performance across dozens of task dimensions, not just how recently it was released or how smart users perceive it to be. And that decision should belong to engineers armed with eval data, not end users who wrongly believe they’ll get better results with the model they personally prefer.
Many AI platforms love to market model choice as a premium feature. “Choose GPT-4o, Claude, or Gemini” sounds empowering and gives users the impression that they will get the best or latest experience. It taps into the same instinct that makes people want to buy the newest phone the week it launches: the feeling that newer and bigger must mean better.
The reality, though, is that most users have no idea which model actually performs best for their specific use case. And even if they did, that answer would likely shift from one query to another. The “best” model for code generation might not be the “best” for bug detection, documentation, or static analysis. There might also be multiple models that are best at different parts of a code review or other task, depending on what kind of code is being reviewed.
Some tasks require greater creativity and reasoning depth; others need precision and consistency. A developer who blindly defaults to “the biggest model available” for coding help, often ends up with slower, more expensive, and less deterministic results. In some cases, a smaller, domain-tuned model will handily outperform its heavyweight cousin.
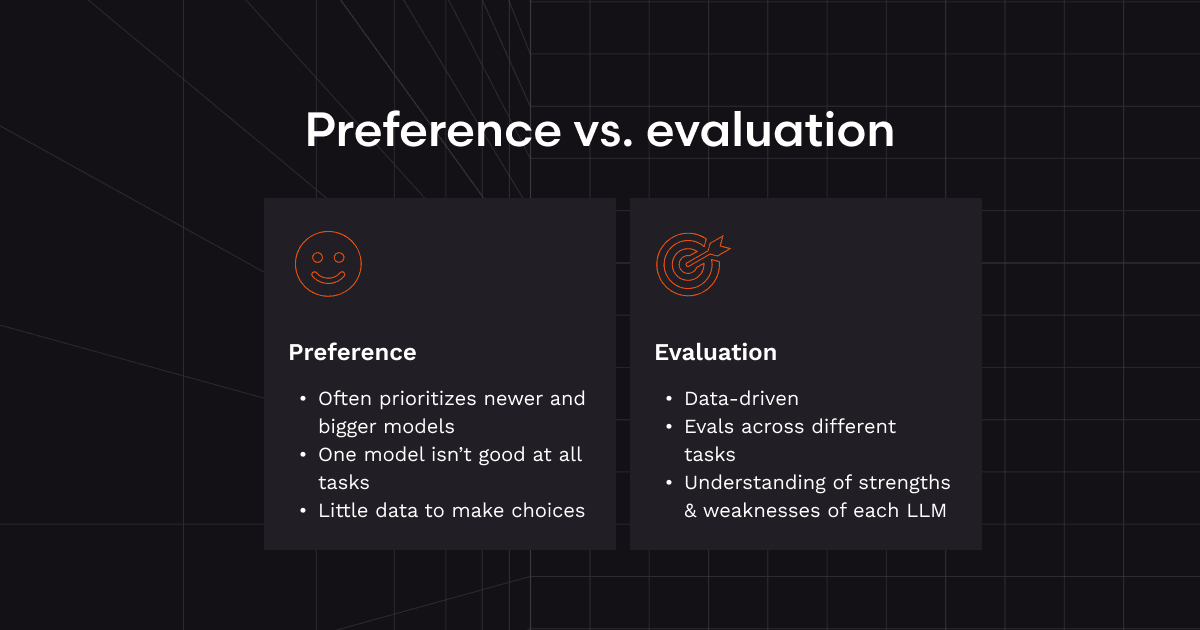
Model selection isn’t a matter of taste… it's a data problem. Behind the scenes, engineers run thousands of evaluations across tasks like code correctness, latency, context retention, and tool integration. These aren’t one-time benchmarks; they’re continuous systems designed to measure how models actually perform under specific, reproducible conditions. The results form a kind of performance map which shows which model excels at refactoring versus summarizing code or which one handles long-context reasoning without drifting off-topic.
End users never see that map. While some might read benchmarks or articles about a model’s performance, most are making decisions blind, guided mostly by hunches, Reddit posts, or vague impressions of “smartness.”
Even if they wanted to, users rarely have the time or infrastructure to run their own evals across hundreds of tasks and models. The result is that people often optimize for hype rather than outcomes… choosing the model that feels cleverest or sounds more fluent, not the one that’s objectively better for the job.
And human perception alone is a terrible way to evaluate model competence. A model that seems chatty and confident can be consistently wrong, while one that feels hesitant might actually deliver the most accurate, reproducible results. Without hard data from evaluations, those distinctions disappear.

One critical drawback to choosing your own model is that no two LLMs think alike. Each model interprets prompts slightly differently. Some are more literal, others more associative; some favor verbosity, others prefer minimalism. A prompt that works perfectly on GPT-5 might completely derail on Sonnet 4.5, leading to hallucinated code, missing context, or an output that ignores key constraints.
Temperature, context length, and formatting differences only make the problem worse. A model with a higher temperature parameter might produce creative explanations but rewrite variable names, while another with stricter formatting rules could break markdown or indentation. These small mismatches can quietly poison a workflow, especially in environments where consistent structure matters most like with code reviews, diff comments, or documentation summaries.
When users choose their own models, they unknowingly disrupt the prompt-engineering assumptions that keep those workflows stable in systems where the prompts are written for the user. Every prompt is tuned with certain expectations about how the model parses instructions, handles errors, and formats its output. Swap out the model and those assumptions collapse.
It’s even harder to navigate in situations where the user writes the prompt themselves, like with AI coding tools. Users rarely have enough context, knowledge, and experience to write effective prompts for each model. However, over time, they might find a few prompting methods that help them get the best out of a particular model. If they later change to a new model, they often find their old prompts aren’t as effective and need to learn from scratch trying to get the best results from that new model.
That’s why well-designed systems rely on model orchestration, not user preference. In review pipelines or agentic systems, predictability is everything. You need each component to behave consistently so downstream tools and other models can interpret the results. Giving users the freedom to swap models isn’t customization; it’s chaos engineering without the safety net.
Once users can switch models at will, all the invisible consistency that makes AI-assisted workflows dependable begins to crumble. The consequences aren’t abstract; they’re measurable and they multiply fast.
Across teams, the first thing you notice is inconsistency. Two developers can run the same review prompt and get completely different feedback. One gets a precise diff comment, the other might get a philosophical musing on the meaning of clean code. That inconsistency makes it impossible to reproduce results, which is deadly for any process that relies on traceability or QA.
Then there’s cost. Larger models burn through tokens faster and often respond slower, introducing both financial waste and latency drag. And when users unknowingly pick models with shorter context windows, the result is truncated inputs or missing context. It’s like asking someone to summarize a novel after reading only half of it.
The smarter alternative to user-driven chaos is dynamic, data-driven routing. That means systems that automatically choose the right model for the right task. Instead of asking users to guess which LLM might perform best, auto-routing engines make that choice in real-time based on metrics, evals, and historical performance.
Think of it as orchestration, not selection. A large model might be routed in for creative reasoning, open-ended problem solving, or complex code explanations. A smaller, domain-tuned model might handle deterministic checks, linting, or static analysis where precision and speed matter more than eloquence. The system continuously evaluates the outcomes tracking correctness, latency, and user feedback in order to refine its routing logic over time.
This approach turns what used to be human guesswork into an adaptive, evidence-based process. The routing system learns which models excel at which tasks, under which conditions, and how to balance cost, speed, and quality.
Advanced teams already operate this way. In CodeRabbit, for example, the orchestration layer sits between the user and the models, using structured prompts, eval data, and performance histories to dispatch requests intelligently. Developers don’t have to think about which LLM is behind a particular review comment. The system has already chosen the optimal one, validated against internal benchmarks.
In short, dynamic routing makes model choice invisible. The user gets consistently high-quality results; the engineers get measurable control and efficiency. Everyone wins. Except the dropdown menu.
The takeaway here is simple: model selection isn’t a feature, it’s a quality control issue. The best results come from systems that make those choices invisibly and are grounded in data, not gut instinct. When model routing is automatic and performance-based, users get consistent, high-quality outputs without needing to think about which model is doing the work.
Every product that puts a “Choose your LLM” dropdown front and center is outsourcing an engineering decision to the least equipped person to make it.
Or, put another way: the best AI tool UI is no LLM dropdown at all.
Curious what it looks like when an AI pipeline optimizes for LLM fit? Try CodeRabbit for free today!



