
David Loker
May 12, 2026
5 min read
May 12, 2026
5 min read
Share
Cut code review time & bugs by 50%
Most installed AI app on GitHub and GitLab
Free 14-day trial
GetStarted in2 clicks.
Let me say something that's uncomfortable coming from someone in my position. AI coding tools are still way worse than humans at generating correct code. And humans were bad enough as it was. We're not even at the point where AI matches human error rates. We’re well past them in the wrong direction.
That's not a reason to stop using AI coding tools. It's a reason to be honest about what comes next.
Here's my prediction. Within the next 12 months, most developers are not going to be looking at the code at all. Let me explain why.
Human code review has been breaking down for years. I used to spend 20-30% of my time reviewing code. That felt like a lot. It wasn't sustainable even then. Now AI-assisted development has accelerated the volume of code coming through review without adding any time to review it. The pressure that was already there is now acute.
That part of the story has been told. What hasn't been told precisely is why the specific problems AI introduces are ones human reviewers are structurally bad at catching, and why that mismatch is what will make human review untenable, not just strained, within the next year.
The data makes this uncomfortably specific.
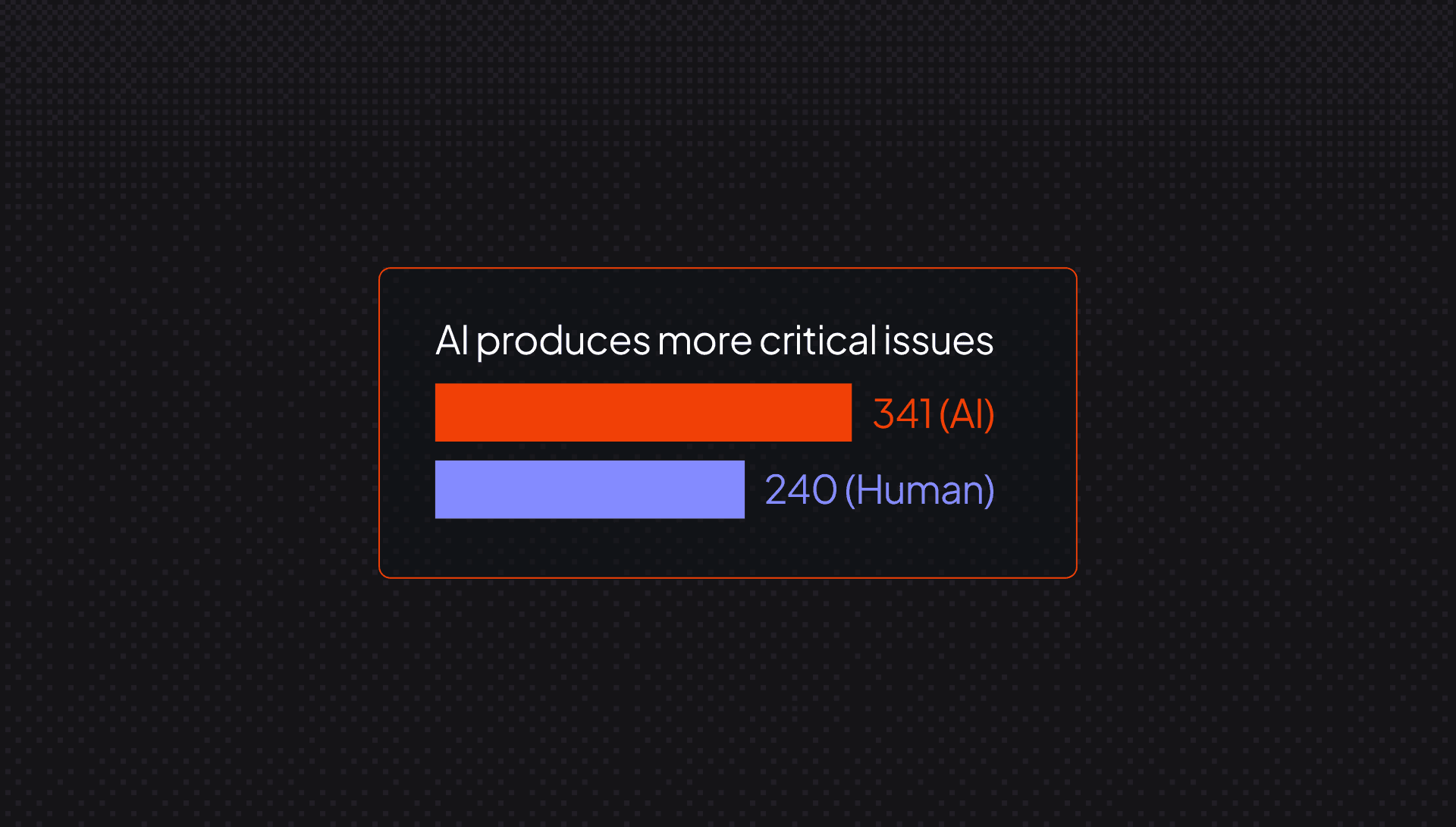
Logic and correctness problems are 75% more common in AI PRs than human ones, according to CodeRabbit's State of AI vs. Human Code Generation Report, which analyzed 470 open-source GitHub pull requests. Error and exception handling gaps are nearly double. These are the failure modes that cause outages, and logic errors are among the most expensive to fix and the most likely to cause downstream incidents. Catching them requires a reviewer to mentally exit the happy path and think through every edge case in code they didn't write and may not fully understand.
Security compounds this further. AI PRs show security issues up to 2.74x higher than human PRs. The most prominent patterns involve improper password handling and insecure object references. These aren't bugs you spot at a glance. Catching them means thinking like an attacker, asking not "does this work?" but "can this be exploited?" That's a different cognitive mode, and not one every reviewer can sustain reliably, especially across a large diff they didn't author.
There's also a readability problem that makes all of this worse. AI-generated code produces more than 3x the readability issues of human code. That’s because it looks clean while quietly violating local conventions and structure. As the report puts it, AI-produced code often looks consistent but violates local patterns around naming, clarity, and structure. That's the worst kind of review problem, one where code that scans fine but requires deep familiarity with the codebase to catch what's actually wrong.
And if you've been using AI code generation heavily, you may genuinely not know the choices that led to the code in front of you. The reasoning is opaque. You're reviewing an output, not a thought process. You don't know where to look because you don't know where the decisions were made.
This is where the conversation about AI and code quality tends to stop. I think it needs to go somewhere else entirely.
What I see happening over the next 12 months is that validation shifts from reading code to verifying intent with Change Stack. Did the thing I wanted to happen, happen? Does the feature behave the way the prompt described? Those are answerable questions that don't require a developer to parse every exception handler in a sprawling diff.
The layer that actually reads the code becomes automated. AI code review, static analysis, security linting, and required test coverage are not stopgaps. The organizations already figuring this out are treating automated review as a structural requirement, not an optional layer. They're building validation pipelines that check outputs against intent. They're not debating whether the code looks right. They've accepted that they won't be the ones looking.
Every company I talk to using AI code generation is viscerally aware of what's happening inside their organization. The excitement was real. The speed gains were real. So is the reality that sets in after a while. That reality is filled with reverting PRs, chasing bugs that are hard to attribute, and fixing things that should have been caught earlier.
The amount of context a model would need to hold simultaneously to generate truly correct code makes perfect output a hard problem to solve quickly. These systems are not going to stop introducing issues anytime soon. We’re going to keep coding with AI. We’re addicted. So now comes the question of whether you have the infrastructure to catch what AI gets wrong before it reaches production. Most teams don’t have that infrastructure, and the gap between AI's speed and the ability to validate its output is widening.

You can't review a 10,000-line PR the way you'd review a hundred-line one. Nobody can. The sooner engineering organizations accept that and build accordingly, the better positioned they'll be when, and not if, the human review model breaks down entirely.
The code will keep coming. The question is what you put between it and production.



