We’ve moved past the era of questioning AI capability. Now, the bottleneck is trust.
In our last post on the topic of Explainability, we drew a sharp line between observability and explainability: what the agent did vs. why it did it. We established that humans need explainability for three distinct jobs: verification, debugging, and auditability.
But where do these explanations actually belong in a developer's day-to-day workflow? If you wait until the agent is completely done to show a summary, you’ve already lost the user. To serve those three critical jobs, explainability must be woven directly into the product workflow. Let’s look at exactly where those moments live.
Three futures, one common thread
To understand why workflow placement matters, look at where the entire AI industry is heading. Anthropic recently published an analysis of AI development scenarios, laying out three distinct paths:

- In the first scenario: Progress stalls, but today's already-powerful models diffuse across the economy.
- In the second scenario: AI labs keep compounding efficiency gains, with humans still setting direction and judging results.
- In the third scenario: AI systems begin recursively improving themselves, and humans move "most of our effort towards oversight, validation, and verification."
Notice what happens to the human role in the (more likely) second and third scenarios. Humans stop being the ones doing the work and instead start verifying it. Anthropic says this is already happening inside their own walls, as more than 80% of the code merged into their codebase is now written by Claude. And as code generation accelerated, human review became the bottleneck. They invoke Amdahl's law — speed up one part of a process, and the overall pace gets capped by the parts that didn't speed up.
That's the thread connecting all three futures. Whichever one we land in, the scarce human activity isn't writing the code, but rather deciding whether to trust it.
The limits of trusting outcomes
For the past year, the industry’s central question regarding AI agents was purely about capability. We asked: Can the agent do X? {X: Fix the bug | Refactor the service | Run the experiment | etc}. We now have our answer from both industry benchmarks and real-world usage data. Consider the sheer velocity of agentic output:
- Commit Volatility: GitHub processed roughly a billion commits in all of 2025; by mid-2026, it was tracking 275 million commits a week (reference) —putting the industry on pace for 14 billion commits this year. Agents are now committing code at machine speed.
- Network Traffic: Cloudflare reported that weekly requests generated by autonomous AI agents more than doubled across its network in a single month (reference).
- Task Horizon: METR’s measurements show that the length of time an agent can reliably operate is doubling roughly every four months. Agents that maxed out at four-minute tasks two years ago can now run for twelve hours unattended (reference).
What drives these sticky adoption curves is a foundational trust in outcomes. Developers have watched agents close enough tickets, fix enough flaky tests, and ship enough working PRs that capability is not even a question anymore.
But "trusting the outcome" has an expiration date.
As agents take on longer tasks with a vastly larger blast radius, the sheer volume of edge cases that fall outside the "agent is usually right" window starts to compound. If your product is hitting this stage, first: congratulations. But second: good luck. You have reached a volume of agentic output that makes line-by-line human review mathematically impossible.
That is the ultimate squeeze. You have more code output than you can humanly manage to verify, yet the stakes of a failure have never been higher. The only way to navigate this AI-first world is to build AI tooling that makes explainability cheap.
Which is to say: every AI tool is on an inevitable path to becoming an explainability tool.

Yes, there's an obvious punchline here: who explains the explainer? An AI tool explaining an AI tool that's explaining another AI tool, all the way down the pews. But the recursion bottoms out in the same place it always has — a human. The point of the explainability stack in our first post on explainability wasn’t to add infinite layers of watchers; it's to make sure that wherever a human sits in that chain, the "why" reaching them is actionable.
The weights are commoditizing across foundational models, so the products that win the next phase won't be the ones with marginally better models. They'll be the ones that make the human at the end of the chain fast, accurate, and a little less miserable ;-)
Explainability workflow
Most teams treat explainability as a post-hoc artifact: the agent finishes, then produces a summary. That's only one-third of the job. True explainability happens at three distinct moments, and each one needs a different kind of "why."
1. Before the work: show me your thinking

The cheapest place to catch a bad decision is before any work happens. Before an agent touches a single file, it should be able to answer: here's what I understood you to be asking for, here's how I'm breaking it into steps, and here's why this approach over the alternatives.
This is the reasoning and planning layer, and it's where intent mismatches surface. Say you ask an agent to "fix the flaky checkout test." One valid plan is to find and fix the race condition causing the flake. Another is to add a retry wrapper. A third is to delete the test entirely. While all three technically "fix” the problem, your intent was only one of them. A plan surfaces these misalignments early on, helping redirect your agent before it burns through your tokens and/or hours of your afternoon trying to debug the aftermath.
The question your product must answer at this stage: Does the agent understand my intent, and does the decomposition of the task align with that intent?
2. During the work: show me your explorations

Agents don't walk a straight line from a prompt to a PR. They branch, hit dead ends, backtrack, and recalibrate. That exploration is invisible in the final diff, but non-negotiable for the user to build trust.
What you want here isn't a raw tool log. Our original post on explainability covered why "show logs" fails everyone. You want the decision trace: which paths the agent explored, which ones turned out to be no-ops, and crucially, what specific piece of information it saw before committing to a branch.
For example, "Explored the caching approach, found that the cache layer is bypassed for authenticated requests, and switched to fixing the query instead" lets a reviewer verify a judgment call in five seconds. If that same information were scattered across 400 lines of raw tool calls, it would be effectively hidden for all intents and purposes even though your AI product “handles explainability”.
The question your product must answer at this stage: Is the agent following the correct chain of thought? Did it pick the right paths, feed them valid inputs, and correctly interpret what came back before moving on?
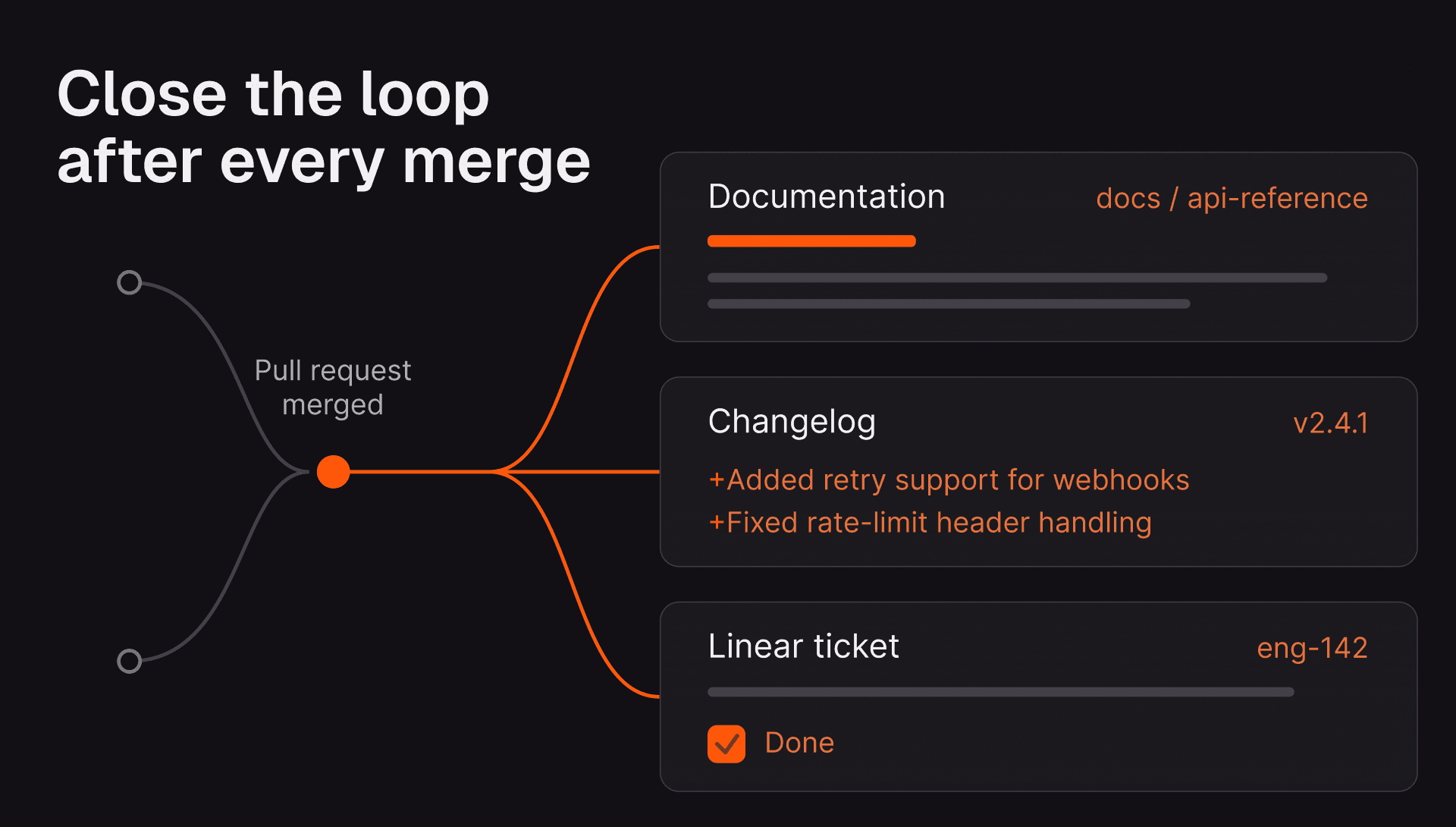
3. After the work: show me the impact

This part of your workflow has the highest stakes, even though it is the most frequently missed. An agent hasn't explained its work until it has explained the all-encompassing consequences of that work, including and especially the ones that aren't visible in the diff right in front of you. A summary of code changes is just a PR description. Only a thorough showcase of the full range of impact is a real explanation. A common product mistake is building the former but believing it is the latter.
Consider an example. An agent opens a PR with a one-line change: it renames an enum value from cancelled to canceled to fix an inconsistent spelling across the codebase. The diff is clean. The type checker is happy. Every test in the repo passes, because the agent dutifully updated them too. By every signal available in the PR, this is the safest change imaginable — a simple typo fix.
Except that value doesn't just live in this repo. It's serialized into events on a queue, and a billing service two hops downstream string-matches on cancelled to stop invoicing a subscription. Nothing errors. Nothing pages. The billing service just quietly stops recognizing cancellations, and customers who canceled keep getting charged.
A reviewer who only sees the diff is verifying a spelling fix. A reviewer who is shown the full blast radius — this value crosses a service boundary, and here is who consumes it — is verifying the actual decision.
This is not a one-off edge case. It's a major gap in how we review code today. Code review has always anchored on what's immediately in front of us, but the consequences of a change rarely respect the boundaries of a diff. This is why we believe explainability at this stage must be held to a high bar: not just "what changed" but a thorough understanding of what the system will do differently because of it.
The question your product must answer at this stage: What does this change actually do — exhaustively, including the parts I cannot see?
Explainability is the product
Stepping back from the three stages in the workflow and looking at what they have in common.
- Before the work, the agent explains its intent.
- During the work, it explains its judgment.
- After the work, it explains its consequences.

These aren't three features to be checked off a roadmap — they are one single obligation, applied at the three points where a human has to make a decision about the agent's work: whether to let it proceed, or take control and maneuver it in a different direction.
That is the real shape of the oversight role the industry is converging on. A human overseeing agents isn't reading every line; they are answering those three questions, over and over, across more output than any person can inspect directly. The quality of their oversight is therefore bounded by the quality of the explanations reaching them.
If the industry's own forecasts are right and the human role converges on oversight and validation, then explainability isn't just a nice-to-have layered on top of AI tools. It is the product.
At CodeRabbit, that's the assumption we're building on. Across everything we ship, the design question is the same: what does the human verifying this work need to know, and at which moment do they need to know it?