Atsushi Nakatsugawa
January 09, 2026
1 min read
January 09, 2026
1 min read
Share
Cut code review time & bugs by 50%
Most installed AI app on GitHub and GitLab
Free 14-day trial
ユーザーに、LLMを選択するドロップダウンを用意するのは、しばしば正しいプロダクト判断に見えます。結局のところ、ユーザーにはお気に入りのモデルがあるかもしれませんし、最新リリースが出た瞬間に試したいと思うかもしれません。
問題が1つあります。各モデルが実際にどこで最も性能を発揮するのかを理解するために、定期的に評価(eval)やベンチマークを回しているMLエンジニアでもない限り、その選択はメリットよりもはるかに大きなデメリットを生みがちです。ユーザーが欲しいと思っているものを与えたつもりでも、結果の一貫性の欠如、トークンの無駄、モデル挙動の不安定さによって、ツールで生み出される成果物の品質が徐々に劣化していきます。
たとえば開発者は、自分でも気付かないまま、特定のタスクに対して遅い、信頼性が低い、あるいはまったく別種の推論パターン向けに調整されたモデルを選んでしまうことがあります。逆に、必要以上に高速なモデルを選んでしまい、タスクを十分に推論しきれないケースもあります。
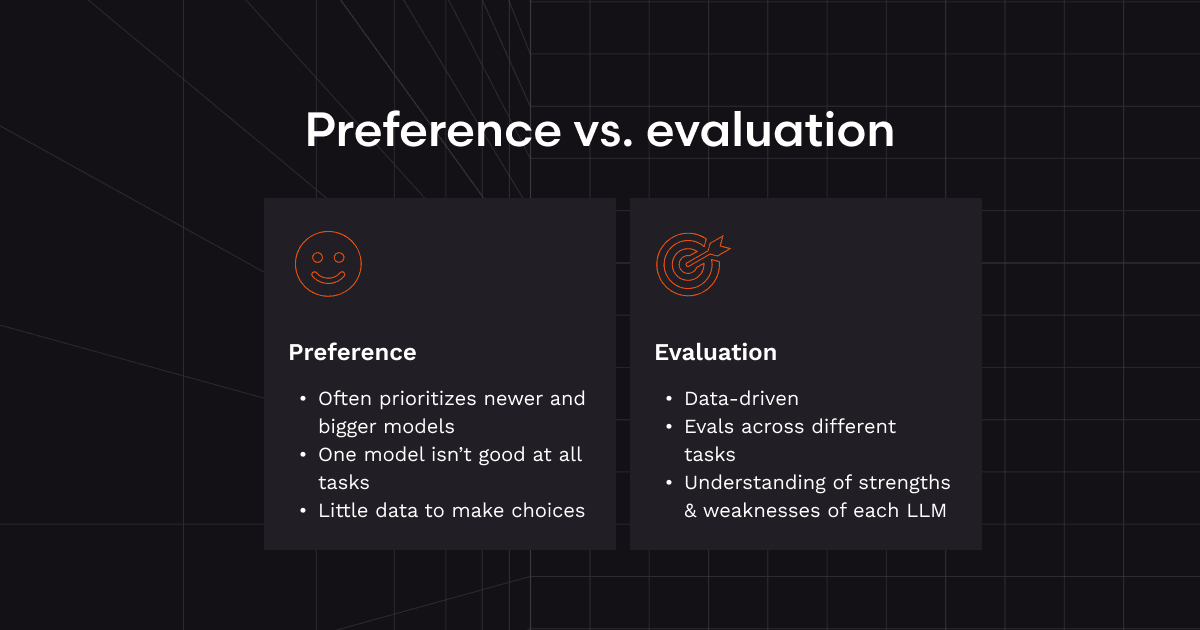
どのモデルを使うかは、個人の好みの問題ではありません。これはシステムレベルの最適化問題です。タスクに適したモデルは、数十のタスク次元にわたる測定可能な性能によって決まります。単にリリースが新しいか、ユーザーが賢そうだと感じるかではありません。そしてその判断は、評価データを持ったエンジニアが行うべきであり、個人的に好むモデルを使えば結果が良くなると誤解しているエンドユーザーに委ねるべきではありません。
多くのAIプラットフォームは、モデル選択をプレミアム機能として売り込みたがります。「GPT-4o、Claude、Geminiを選べます」という耳触りの良いメッセージは、ユーザーに「最高の体験」「最新の体験」が得られるという印象を与えます。これは、新しいスマホが発売された週に買いたくなるのと同じ本能に訴えかけます。新しいものや大きいものは良いはずだ、という感覚です。
しかし現実には、ほとんどのユーザーは、自分のユースケースでどのモデルが本当に最も性能が良いのかを知りません。たとえ知っていたとしても、その答えはクエリごとに変わる可能性が高いです。コード生成における「最良」のモデルが、バグ検出、ドキュメント作成、静的解析でも「最良」とは限りません。また、レビュー対象のコードの種類によって、コードレビューや他のタスクの異なる部分に対して最適なモデルが複数存在することもあります。
タスクによっては創造性や深い推論が必要であり、別のタスクでは精度と一貫性が求められます。コーディング支援において「利用可能な最大モデル」を盲目的にデフォルトにすると、遅く、高コストで、決定性の低い結果になりがちです。場合によっては、小さくてもドメインに合わせて調整されたモデルが、巨大なモデルを遥かに上回ることもあります。
モデル選択は好みの問題ではなく、データの問題です。裏側では、エンジニアがコードの正しさ、レイテンシ、コンテキスト保持、ツール統合などのタスクに対して何千回もの評価を走らせています。これは一度きりのベンチマークではなく、特定の再現可能な条件下において、モデルが実際にどう動くかを測定し続ける継続的な仕組みです。その結果は、たとえば「リファクタリングに強いモデル」と「コード要約に強いモデル」や、「長いコンテキスト推論で話が逸れにくいモデル」などを示す、ある種の性能マップを形成します。
エンドユーザーはその性能マップを見られません。ベンチマークやモデル性能の記事を読む人もいるかもしれませんが、多くの人は勘、Redditの投稿、あるいは「賢そう」という定性的な印象に導かれて、ほぼ手探りで意思決定しています。
たとえやる気があっても、ユーザーが何百ものタスクとモデルに対して自前で評価を回す時間やインフラを持つことは稀です。その結果、人は成果ではなく話題性で最適化しがちです。つまり、客観的に仕事に向いているモデルではなく、最も賢そうに感じる、あるいは最も流暢に見えるモデルを選んでしまいます。
そして、人間の印象だけでモデルの能力を評価するのは最悪の方法です。饒舌で、自信満々に見えるモデルが実は間違っていることもあれば、ためらいがちに見えるモデルが最も正確で再現性の高い結果を出すこともあります。評価に基づく一貫したデータがなければ、そうした差は見えなくなります。

自分でモデルを選ぶことの重大な欠点の1つは、LLM同士が同じように考えるわけではないことです。モデルごとにプロンプトの解釈が微妙に異なります。より字面通りに受け取るものもあれば、連想的なものもあります。冗長さを好むものもあれば、最小限を好むものもあります。GPT-5では完璧に機能するプロンプトが、Sonnet 4.5では完全に破綻し、ハルシネーション的なコード、コンテキスト欠落、重要な制約を無視した出力につながることもあります。
温度(temperature)、コンテキスト長、フォーマット差分は、この問題をさらに悪化させます。温度が高いモデルは創造的な説明を生成する一方で、変数名を書き換えてしまうかもしれませんし、フォーマット規則が厳しい別のモデルはMarkdownやインデントを壊すかもしれません。こうした小さな不整合が、特にコードレビュー、diffコメント、ドキュメント要約のように一貫した構造が重要な環境では、ワークフローを静かに汚染していきます。
ユーザーが自分でモデルを選ぶと、プロンプトがユーザー向けに書かれているシステムにおいて、そのワークフローを安定させていたプロンプトエンジニアリング上の前提を、本人が気付かないまま破壊します。すべてのプロンプトは、モデルが指示をどう解析し、エラーをどう扱い、出力をどう整形するかについて、特定の期待を前提に調整されています。モデルを入れ替えると、その前提は崩壊します。
AIコーディングツールのように、ユーザー自身がプロンプトを書くケースではさらに難しくなります。ユーザーは、モデルごとに有効なプロンプトを書くための十分な文脈、知識、経験を持っていないことがほとんどです。ただ時間が経つにつれ、特定のモデルから最大限の成果を引き出すプロンプト手法をいくつか見つけることはあります。しかし新しいモデルへ切り替えると、以前のプロンプトが効かなくなり、最初から学び直す羽目になりがちです。
だからこそ、良く設計されたシステムはユーザーの好みではなく、モデルオーケストレーションに依存します。レビュー・パイプラインやエージェント的システムでは、予測可能性がすべてです。各コンポーネントが一貫して動作しないと、下流のツールや別のモデルが結果を解釈できません。ユーザーにモデルを差し替える自由を与えることは、カスタマイズではありません。安全網のないカオスエンジニアリングです。
ユーザーが自由にモデルを切り替えられるようになると、AI支援ワークフローを信頼できるものにしていた見えない一貫性が崩れ始めます。影響は抽象的な話ではありません。測定可能で、しかも急速に増幅します。
チーム横断で最初に目立つのは不一致です。同じレビュー用プロンプトを流しても、開発者AとBでまったく違うフィードバックが返ってきます。片方は精密なdiffコメントを得る一方、もう片方はクリーンコードの意味についての哲学的な考察を受け取るかもしれません。この不一致は結果の再現性を破壊し、トレーサビリティやQAに依存するプロセスにとって致命的です。
次にコストです。大きなモデルはトークン消費が多く、応答も遅くなりがちで、金銭的な無駄な損失とレイテンシの悪化を招きます。さらにユーザーが短いコンテキストウィンドウのモデルを選んでしまうと、入力が途中で切れたり、必要な文脈が欠落したりします。小説を半分しか読まずに要約しろと言うようなものです。
ユーザー主導の混乱に対するより賢い代替案は、動的でデータ駆動のルーティングです。これは、システムがタスクに応じて適切なモデルを自動的に選ぶことを意味します。ユーザーに「どのLLMが最適か」を当てさせるのではなく、オートルーティングエンジンが、メトリクス、評価(eval)、過去の実績に基づいてリアルタイムに判断します。
これは選択ではなくオーケストレーションだと考えてください。大きなモデルは創造的推論、自由度の高い問題解決、複雑なコード説明に割り当てられるかもしれません。小さくてドメイン調整されたモデルは、精度と速度が重要な決定的チェック、Lint、静的解析を担うかもしれません。システムは正確性やレイテンシ、ユーザーフィードバックを追跡しながら成果を継続的に評価し、時間をかけてルーティングロジックを洗練します。
このアプローチは、人間の当て推量だったものを、適応的でエビデンスに基づくプロセスへと変換します。ルーティングシステムは、どの条件でどのタスクにどのモデルが強いのか、そしてコスト、速度、品質のバランスをどう取るかを学習します。
先進的なチームはすでにこの形で運用しています。たとえば CodeRabbit では、オーケストレーション層がユーザーとモデルの間に入り、構造化プロンプト、評価データ、性能履歴を用いてリクエストを賢く振り分けます。開発者は、特定のレビューコメントの背後にどのLLMがいるのかを意識する必要がありません。システムがすでに内部ベンチマークで検証された最適解を選んでいます。
要するに、動的ルーティングはモデル選択を不可視化します。ユーザーは一貫して高品質な結果を得られ、エンジニアは測定可能な制御と効率を手に入れます。勝者は全員です(ドロップダウンメニュー以外は)。
結論は単純です。モデル選択は機能ではなく、品質管理の問題です。最良の結果は、その選択を見えないところで行い、勘ではなくデータに基づくシステムから生まれます。モデルルーティングが自動化され、性能ベースになれば、ユーザーはどのモデルが動いているかを考えることなく、一貫して高品質な出力を得られます。
「LLMを選ぶ」ドロップダウンをプロダクトの中心に置くということは、エンジニアリング上の意思決定を、それを行うのに最も不向きな人に丸投げしているということです。
別の言い方をすれば、最高のAIツールUIとは、LLMのドロップダウンが存在しないUIです。
AIパイプラインがLLM適合を最適化すると、どんな見え方になるか気になりますか? CodeRabbit を今すぐ無料で試してください!