

Brandon Gubitosa
June 24, 2026
9 min read
June 24, 2026
9 min read
Share
Cut code review time & bugs by 50%
Most installed AI app on GitHub and GitLab
Free 14-day trial
Pairing with a coding agent looks like the old Extreme Programming (XP) practice with a faster partner. The resemblance is misleading. The roles invert, and the next step carries the risk.
In the agentic software development lifecycle (SDLC), AI coding agents take on implementation tasks while humans steer, review, and decide what ships. In classic pair programming, one person drives and one navigates. When your pair is an agent, you stop driving. The agent takes the keyboard, and you become the navigator full-time.
Replit CEO Amjad Masad draws the line in the navigator model. Older assistant-style tools still leave you as "the driver," and agents flip that. Masad frames the new arrangement cleanly: "It's the AI's job to be fast, but it's your job to be good."
The slogan sounds fine until you do the math on what "your job to be good" means at agent throughput. When the agent writes most of the code, review becomes the merge gate. You start skimming, defects slip through, and stability suffers while velocity looks better than ever. The navigator role gets harder when one engineer pairs with several agents, and the agent that wrote the code can't be the only thing that judges it.
The inversion plays out in four moves, and every one of them lands on the same person: the reviewer.
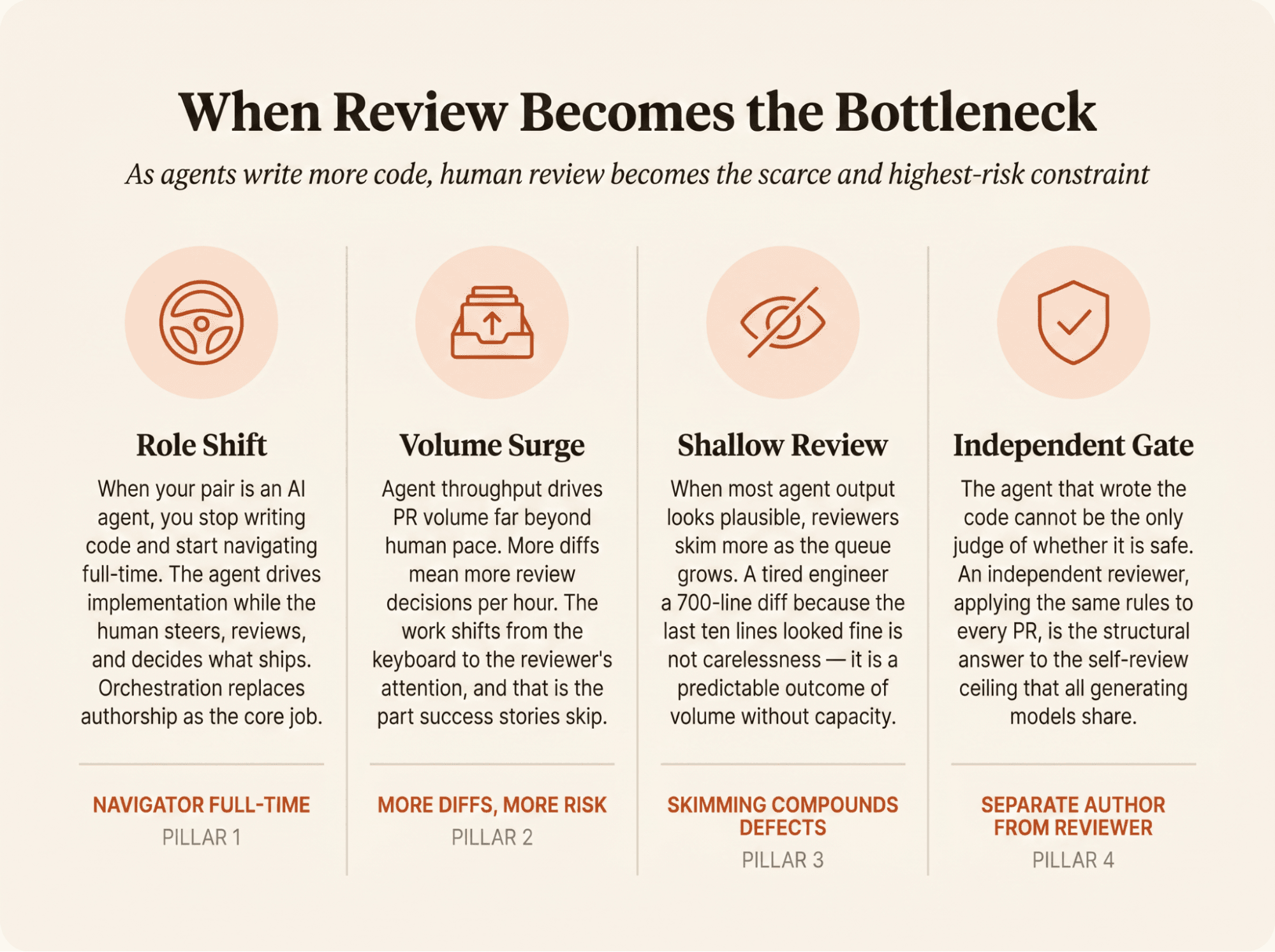
The mechanics are simple and the consequences are not. You stop typing and start directing. You delegate a task, the agent writes the code, and you decide whether the result is good enough to merge. Orchestration replaces authorship as your main job, and oversight replaces typing as your core skill. Writing a good brief, reading the agent's output, and catching the edge cases it missed is now where your time goes.
Monthly merged pull requests (PRs) kept climbing, from 35M to 43.2M, with more than 986M commits in 2025, up 25% year over year. The developer role is moving toward orchestration and verification, where you produce less code directly and spend more time making generated work trustworthy enough to ship.
More code means more diffs and more review decisions. The work moved from the keyboard to the reviewer's attention, and that's the part the success stories skip.
Review fails quietly when a tired senior engineer approves a 700-line agent diff because the last ten lines looked fine.
Plausible output is the trap. When most of what an agent produces looks right, positive experience makes reviewers less vigilant. The reviewer doesn't need to become careless for quality to fall. They only need to skim more often as the queue grows.

The queue was already a constraint before agents arrived. Taskrabbit cut merge time by 25%, dropping the average PR cycle from 10 days to 7 before adopting coding agents, which shows review can gate cycle time even at human volume. Agent volume makes that gate the dominant constraint, and a dominant constraint under load is exactly where skimming starts.
CodeRabbit's review of 470 PRs found 10.83 issues per AI co-authored PR versus 6.45 per human-only PR, 1.7x more findings per PR. More findings per PR means more to catch in each pass, right when each pass is getting shallower. Larger changes are harder to review honestly than small ones, especially when the diff is mechanically repetitive, and agents are good at producing large, similar-looking changes that invite a shallow pass unless the team constrains batch size and protects reviewer attention.
DevOps Research and Assessment (DORA) found AI adoption associated with weaker delivery outcomes. Its 2024 report tied a 25% increase in AI adoption to an estimated 1.5% decrease in delivery throughput and a 7.2% reduction in delivery stability. DORA also found that larger batch sizes slow review and are "more prone to creating system instability," because AI lets developers generate code much faster.
In 2025, DORA's follow-up report showed throughput recovering but stability still moving the wrong way.
Developers already feel the trust problem. Among roughly 50,000 respondents, 46% actively distrust the accuracy of AI output, up from 31% in 2024. The people doing the most reviewing trust the output the least, so review-heavy workflows have to keep their skepticism while queues reward speed.
When you pair with one agent, you can navigate in real time. When you run six, real-time navigation is gone. So where does supervision go?
Parallel agent work changes the supervision pattern. Your obligation stays blunt: you are still responsible for delivering code that works. But the feedback loop is no longer one continuous pairing session. It becomes a sequence of task handoffs, diffs, comments, and merge decisions.
The pairing metaphor breaks down at many-agent scale. With one agent, you can watch it work and steer continuously. With several, sessions are isolated and you have to reconstruct intent from the artifact each agent leaves behind. Async handoffs matter more than live pairing now. Each agent needs enough structured context for the next step, and each diff needs enough explanation for a reviewer to make a real decision.
At the many-agent scale, the diff becomes where supervision happens. You no longer catch every wrong turn while watching the agent type. The 90th-percentile finding makes that risk concrete: 26 issues in AI co-authored PRs versus 12.3 in human-only PRs, a 2.11x gap. Catching those issues from the diff alone depends on something the diff doesn't carry by itself, the context that tells a reviewer what the change was supposed to do.
Drift is the cost of forgetting. Without a shared, committed record of how your team works, every agent session starts from zero and rediscovers your conventions by trial and error.
Without shared context, agents drift from project conventions, repeat old mistakes, and force you to re-explain the same standards. CodeRabbit's AI code study found readability issues were 3.15x more common in AI co-authored PRs, the kind of convention drift that compounds across a repo.
Context engineering means keeping the instructions and review guidance that agents and reviewers share in persistent, version-controlled artifacts. Stack Overflow's coding guidelines for agents put it plainly: "Explicitly put all these rules in your agents.md and check them into a standard repo." Treat it as a team discipline. The rules are owned, version-controlled, and distributed through the repo instead of living in one developer's personal setup.
Reviewer guidance and agent instructions need the same home. If the standards governing how your team writes code with AI also govern how every PR gets reviewed, you stop re-explaining yourself. The agent's output arrives closer to right the first time. CodeRabbit ingests .cursorrules and equivalent instruction files, and CodeRabbit Learnings turn PR-comment feedback into future review guidance, so future reviews inherit prior feedback instead of starting over.
Self-review by the generating model has a structural ceiling. The author of the change should not be the only reviewer of the change.
A model can often improve a result when it gets external feedback, execution output, or a separate critique. That differs from reliably finding its own mistake unaided. Don't let the same agent that produced the diff decide whether the diff is safe.
Security creates the same separation requirement. AI-generated code can introduce risks when teams incorporate it without proper review. When teams accept generated code too quickly, insecure patterns, missing checks, and flawed assumptions move downstream before a human has understood what changed. CodeRabbit's AI PR analysis found security findings were 1.57x more common in AI PRs.

Abnormal AI scaled verification across AI-generated and manually written code with a 65%+ acceptance rate on critical-severity comments. Teams need an independent reviewer, one that didn't write the diff and applies the same rules to every PR.
CodeRabbit operates as an independent verification layer, reviewing the diff with full codebase context without trusting the generator to grade its own work.
When the cost of generating code approaches zero, counting generated artifacts tells you almost nothing about system health. Lines of code can reward verbosity over clarity, and PR volume can climb while delivery slows down.
Developer productivity can't be captured by a single metric. The measurement system has to account for speed, quality, collaboration, and outcomes together.
DORA's 2024 update added a fifth metric, deployment rework rate, the share of deployments that involve unplanned bug-fix work. DORA also warns that coding-speed gains get swallowed by downstream bottlenecks in testing, security reviews, and deployment.
Use four metrics that a commit log can't show:
Together these four show whether speed is buying you delivery or just motion. They are the honest scoreboard for the constraint the rest of this piece keeps circling back to: review.
Pairing with an agent makes review the scarce resource. The driver and navigator swap seats. At many-agent throughput, navigation becomes a review queue that one tired human can't honestly clear.
Persistent shared context keeps agents aligned. Better metrics keep you honest about whether quality is holding. An independent reviewer, separate from the model that wrote the code, keeps the author from being the only judge of its own diff.
For agent-heavy review, CodeRabbit reviews with codebase context and team conventions across PRs, the IDE, and the CLI, and ensures that every line still earns its merge.



