CodeRabbit is now in the Claude Marketplace!Learn more

Brandon Gubitosa
June 19, 2026
7 min read
June 19, 2026
7 min read
Share
Cut code review time & bugs by 50%
Most installed AI app on GitHub and GitLab
Free 14-day trial
Be honest with yourself for a minute. When was the last time you fully understood a pull request that was not yours in the last quarter?
Seriously, did you trace the logic, check the ticket, inspect the edge cases, and think through what would happen in production? Or did you skim, get the gist, look for obvious red flags, and approve because you trusted the author and were slammed with “urgent” reviews.
That is the real state of code review on most teams. Engineers have not stopped caring about code quality. The problem is that the volume of code has outpaced the amount of attention and time any human can give it. Larger pull requests sit for days, architectural feedback gets rarer, and careful review turns into pattern matching once the diff gets larger than what one person can realistically hold in their head.
Open source maintainers live with this daily now that contributing to projects became cheap, but reviewing code didn’t follow that path. A human still reads every pull request, deciphers what changed, understands why it was built that way and decides if it conflicts with how the rest of the codebase works.
That is the reality of the new software development lifecycle (SDLC), reviewing agent generated code is slowing teams down and pushing ROI from coding agents further out.
Teams are applying the old review model they used for human-written code to review code written by agents. A human reviewer can only hold so much code, context, and intent in their head at once before review turns into pattern matching.
We’ve rebuilt our code review interface for the agentic SDLC to help developers fully understand what is changing, why those changes matter, what the risk is, and what is actually about to ship.
If you have been reviewing code for the last decade, you know the quiet truth that the process of reviewing code has always been a little broken even before introducing AI to the equation.
Code review has always depended on a reviewer reconstructing intent from another person's brain. The author knows why the change exists and what behavior they meant to introduce. The reviewer gets a diff and has to reverse-engineer that logic in their own head before they can even start evaluating whether the change is correct.
AI amplifies the bottlenecks in code review across engineering teams. Now, teams are pushing far more code through the same interfaces designed for human-written code in larger and harder to understand diffs, often with less confidence that the author who opened up the pull request even fully understands the impact of the change. That is where teams discover that reviewing human-written code and AI-generated code are different jobs.
AI generated code often reflects pattern completion and can miss codebase conventions, constraints, and architectural logic. The failure modes of AI generated code are not subtle. Our own research found that logic and correctness problems are 75% more common in AI pull requests than in human ones. Security issues can be as high as 2.74x, and readability issues are more than 3x higher.

Those are not the kind of defects you catch by casually scanning a diff and are issues that require deep context, careful reasoning, and time that most reviewers no longer have since the role of senior engineers has shifted to validating intent, pressure-testing risk and deciding whether the change should exist at all.
These pressures aren't just limited to human contributions, however. They highlight a universal reality. Human-written code and AI-generated code arrive through different paths, but fail in the same place.
Intent is still missing from the code review surface. The real bottleneck in code review, whether the code is human- or AI-generated, is understanding what the change was supposed to do, what constraints mattered, what could break, and whether the final behavior matches the original goal. Code review has always forced people to infer that from a diff, and AI makes the gap far more obvious.
The underlying factor in all of this is that the interface for reviewing code has not kept up with the shift toward agents writing a growing share of code. Current interfaces still assume that showing changed files in order is enough for someone to reconstruct the intent. It was a weak assumption before AI, and it is an even worse one now.
For code review to hold up in agentic workflows, it cannot exist in a raw diff viewer. It has to become a system that helps reviewers understand intent, isolate risk, and focus attention where judgment actually matters.
In agentic workflows, we must pivot from line-by-line inspection to intent validation. We need to answer: Did the system build what we meant to build? Does the change respect existing codebase constraints? This shift is essential because the volume of AI-generated code has long since outstripped our ability to inspect it manually.
In order to review code and understand intent better, teams need a verification layer that carries intent forward. It should make the shape of a change legible, connect related work across files, surface the non-obvious risk, and help a reviewer move through a pull request in the order that makes sense instead of the order the filesystem happens to return.
This shift matters because the bottleneck in code review has always been understanding intent well enough to judge whether a change is right, whether it is safe, and whether it actually does what the team intended.
AI did not change the nature of that bottleneck, it raised the rate of output dramatically and teams now have to understand intent faster than the old review process was ever designed to support.
Reviewers still need to see the shape of a change, the order in which they should be read, the dependencies that matter, and the places where human judgement should slow down. When code generation accelerates, code review has to become better at carrying intent forward, otherwise teams do not leverage and just move the bottleneck downstream.
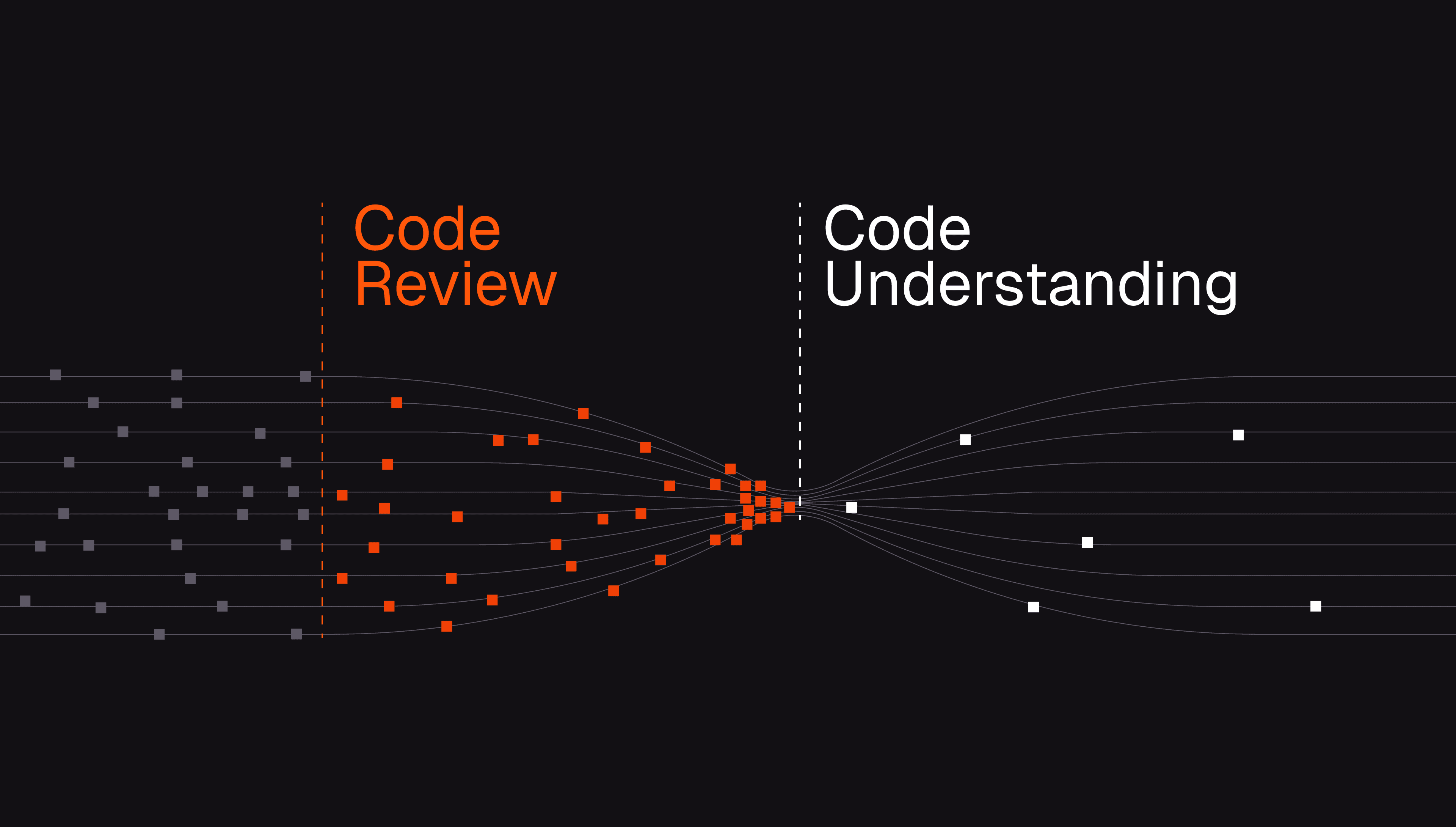
That is the direction behind CodeRabbit Review. Instead of leaving a pull request as a flat list of files, it reorganizes the change into logical cohorts and ordered layers, anchors those layers to real code ranges, and adds diagrams when a visual explanation makes the change easier to understand.
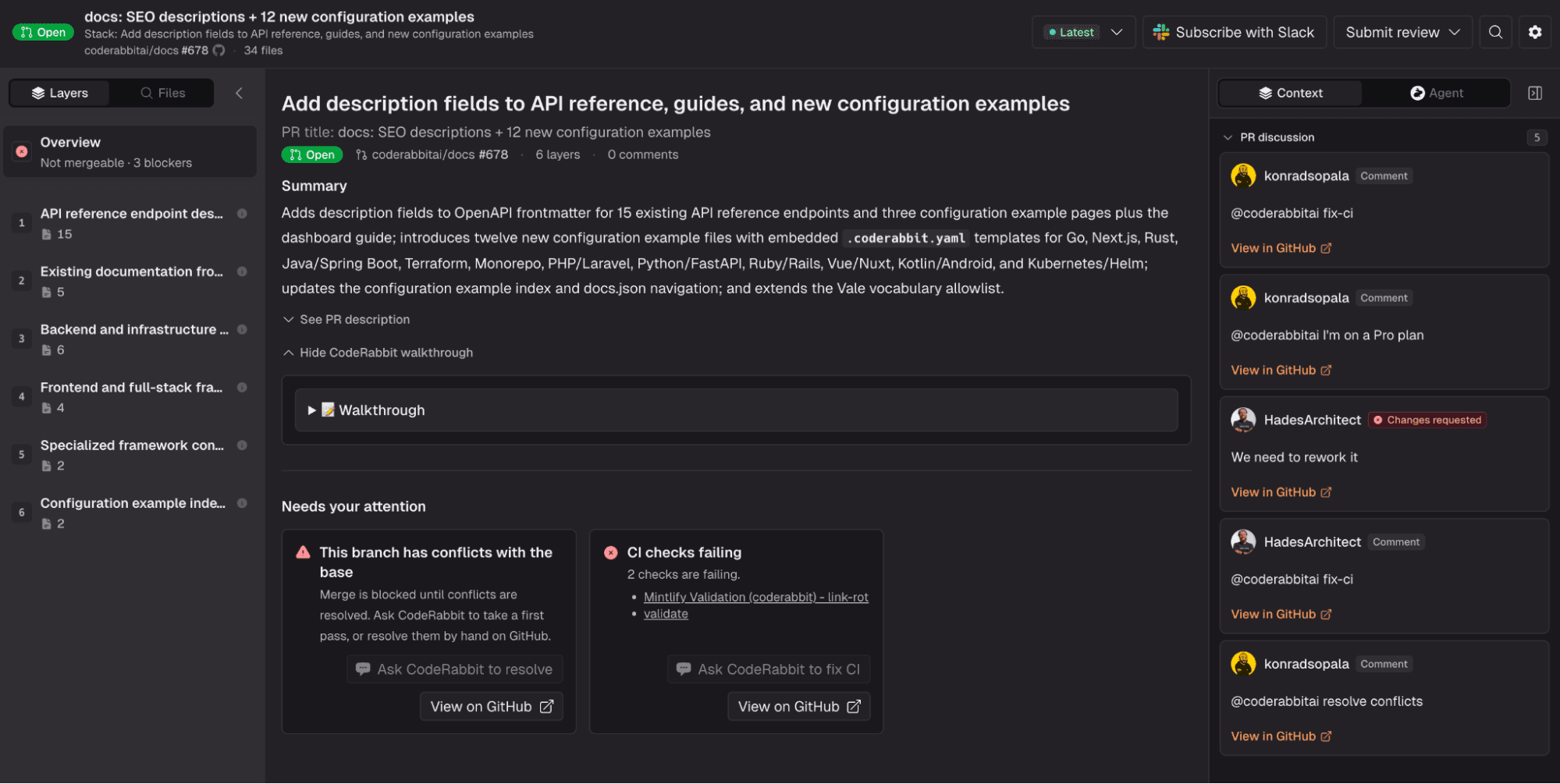
This means understanding relationships across changed blocks, mapping dependencies, and turning a diff into an explainable walkthrough instead of a pile of lines to review. The goal is not to flood teams with more AI commentary, but to remove the reconstruction step that has made code review slow and fragile for years.
Try CodeRabbit Review on the next PR. CodeRabbit Review is free for a limited time for every CodeRabbit user. You can find it by clicking Review Change Stack in the CodeRabbit PR summary comment.



